E-mail Alert
E-mail Alert RSS
RSS-
摘要
本文提出了一种基于双交叉注意力融合的Swin-AK Transformer (Swin Transformer based on alterable kernel convolution)和手工特征相结合的智能手机拍摄图像质量评价方法。首先,提取了影响图像质量的手工特征,这些特征可以捕捉到图像中细微的视觉变化;其次,提出了Swin-AK Transformer,增强了模型对局部信息的提取和处理能力。此外,本文设计了双交叉注意力融合模块,结合空间注意力和通道注意力机制,融合了手工特征与深度特征,实现了更加精确的图像质量预测。实验结果表明,在SPAQ和LIVE-C数据集上,皮尔森线性相关系数分别达到0.932和0.885,斯皮尔曼等级排序相关系数分别达到0.929和0.858。上述结果证明了本文提出的方法能够有效地预测智能手机拍摄图像的质量。
Abstract
This paper proposes a smartphone image quality assessment method that combines the Swin-AK Transformer based on alterable kernel convolution and manual features based on dual attention cross-fusion. Firstly, manual features that affected image quality were extracted. These features could capture subtle visual changes in images. Secondly, the Swin-AK Transformer was presented and it could improve the extraction and processing of local information. In addition, a dual attention cross-fusion module was designed, integrating spatial attention and channel attention mechanisms to fuse manual features with deep features. Experimental results show that the Pearson correlation coefficients on the SPAQ and LIVE-C datasets reached 0.932 and 0.885, respectively, while the Spearman rank-order correlation coefficients reached 0.929 and 0.858, respectively. These results demonstrate that the proposed method in this paper can effectively predict the quality of smartphone images.
-
1. 引 言
图像质量评价 (Image quality assessment, IQA)分为两大类:主观评价和客观评价。主观评价主要依赖于人们观察图像后给出的评分,虽然接近用户的真实感受,但此方法耗时且成本高昂,不易于在实际应用中广泛采用[1];相反,客观评价使用算法模拟人眼视觉系统 (human visual system, HVS)的特点,并对图像的质量进行评价,这种方法效率高,极大地提高了图像质量评价的实用性和广泛应用。
综上所述,传统手工特征方法[12]在应对智能手机图像中的复杂失真时表现较差,难以捕捉图像的细微特征;现有的基于深度学习的图像质量评价方法也未能完全适应智能手机图像的多样性。因此,开发能够全面反映智能手机图像整体内容和细节特征的评价方法成为了一个亟待解决的问题。本文针对智能手机拍摄的图像常常受到噪声、压缩伪影以及复杂光照条件的影响,而导致图像出现质量问题,提出了基于Swin-AK Transformer (Swin Transformer based on alterable kernel convolution)和手工特征进行双交叉融合的智能手机拍摄图像客观质量评价方法,用于评价智能手机拍摄图像的质量。此模型首先提取影响智能手机拍摄图像质量的4种手工特征。然后,使用Swin-AK Transformer提取图像的深度特征,其中AKconv 的动态卷积核调整机制学习图像的局部特性 (如噪声分布、光照不均匀和边缘强度等),动态调整卷积核的权重,更好地适应噪声和弱光环境下的细节表现。此外,AKconv的多尺度调整能力有效捕获了智能手机图像中模糊和细节丢失的问题,确保从全局结构到局部细节的全面表征能力。接着,利用双交叉注意力融合模块 (dual attention cross fusion, DACF)将上述两种特征进行融合,DACF 模块使用通道注意力和空间注意力机制,针对智能手机拍摄图像的特点,更有效地融合手工特征和深度特征,弥补单一特征表征能力的不足。通道注意力机制能够分析智能手机图像中纹理和光照动态,可以平衡手工特征的全局统计信息与深度特征的局部细节。空间注意力机制精准定位智能手机图像中的关键区域,如细节纹理和边缘区域,同时抑制伪影和噪声的干扰。通道注意力与空间注意力协同作用,能够充分捕捉智能手机图像的全局与局部特性。最后,得到智能手机拍摄图像的质量分数。
早期的图像质量评价方法大多为通用型方法,虽然在一般场景中表现较好,但在面对智能手机拍摄的复杂图像失真时存在局限性,尤其是在处理复杂非线性失真时效果较差。Ke等[2]提出了一种多尺度的图像质量评价方法,虽然能够处理不同分辨率和长宽比的失真图像,避免了传统卷积神经网络输入固定图像尺寸导致的效果下降问题。Varga等[3]采用了一种基于全局和局部图像统计特征的无参考通用型图像质量评价方法,该方法模拟了人类视觉系统感知图像质量的特点,并将图像的全局统计特征和局部统计特征组合在一起。Jain等[4]提出了一种无参考通用型图像质量评价方法,此方法结合了自然场景的统计特征和卷积神经网络来预测图像质量的分数。Shao等[5]针对图像内容失真的特点,提出了一种新的无参考通用型图像质量评价方法,该方法使用内容感知和失真推理网络有效预测了合成和真实失真图像的质量分数。Zhao等[6]提出了一种面向无参考图像质量评价的质量感知预训练模型,旨在克服标记数据稀缺的问题来提升性能。对于智能手机拍摄图像,通用型图像质量评价方法的效果普遍较差,原因在于智能手机图像的拍摄环境多样化,以及不同品牌和型号摄像头的技术差异。这使得用户难以高效挑选高质量的图像,因此开发专门针对智能手机图像特点和失真类型的质量评价方法显得尤为重要。
随着智能手机摄像技术的快速发展,人们越来越习惯使用智能手机进行拍摄,产生了大量的图像。这些图像广泛应用在社交媒体、电子商务等领域中,准确评价智能手机拍摄图像的质量变得尤为重要。然而,由于智能手机拍摄条件的多样性和随机性,准确地评价图像的质量成为一个难点。
近几年,越来越多的研究专注于智能手机拍摄图像质量评价,Fang等[7]首次开展了智能手机摄影感知质量评价的研究,并创建了一个包含11125张由66款智能手机拍摄的图像数据集 (smartphone photography attribute and quality, SPAQ)。Yuan等[8]提出了一种专门针对智能手机摄影图像的质量评价方法,此方法结合了美学和人眼视觉感知的特性,从曝光、噪声、颜色和纹理这四个方面对图像的质量进行评价。该方法只提取了手工特征,没有使用深度学习,从而限制了此方法的适应性和泛化能力。Zhou等[9]提出了一种多指标智能手机图像质量评价模型,根据人眼视觉感知的特点,使用两种图像裁剪方法获取输入图像,并使用回归分析来预测颜色、纹理、噪声和曝光的分数。Huang等[10]提出了一种多任务深度卷积神经网络模型,用于智能手机拍摄图像的无参考质量评价。在此模型中,把场景类型的检测作为辅助任务,但这一任务的准确性并不稳定,场景类型的分类错误可能会影响整体的质量评价。Yao等[11]提出了一种基于残差块的卷积神经网络 (convolutional neural network, CNN)来进行智能手机拍摄图像的无参考质量评价,该模型生成显著性区域并选取图像的特定子区域作为输入信息,这种处理方式会忽略全局的图像信息,从而导致质量评价结果不具有全局性。以上方法研究了智能手机拍摄图像相关属性的评价,并没有进行图像整体内容的质量评价,而本文研究了智能手机拍摄图像整体内容的质量评价。
2. 本文方法
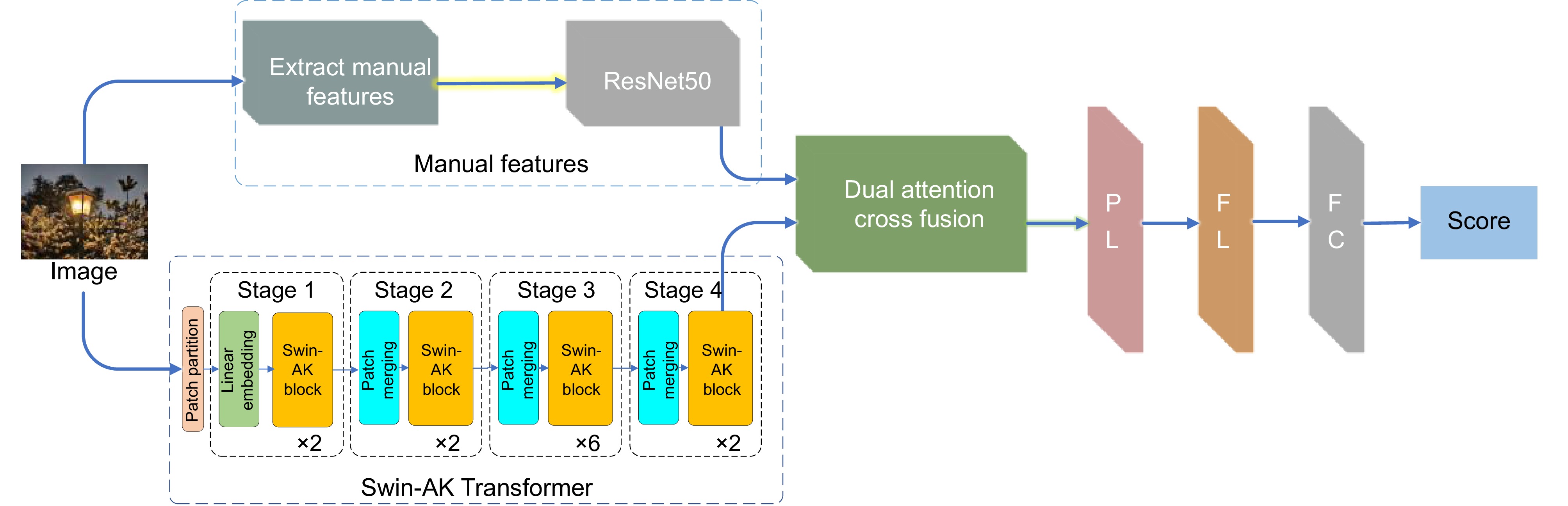
本文提出的基于Swin-AK Transformer的智能手机拍摄图像质量评价方法的网络架构主要分为三部分,如图1所示。在图1中,第一部分先提取手工特征,然后再将这些特征送入到ResNet50去提取更加复杂的特征信息;第二部分使用Swin-AK Transformer提取深度特征;第三个部分使用双交叉注意力融合模块来融合前两个部分的特征。
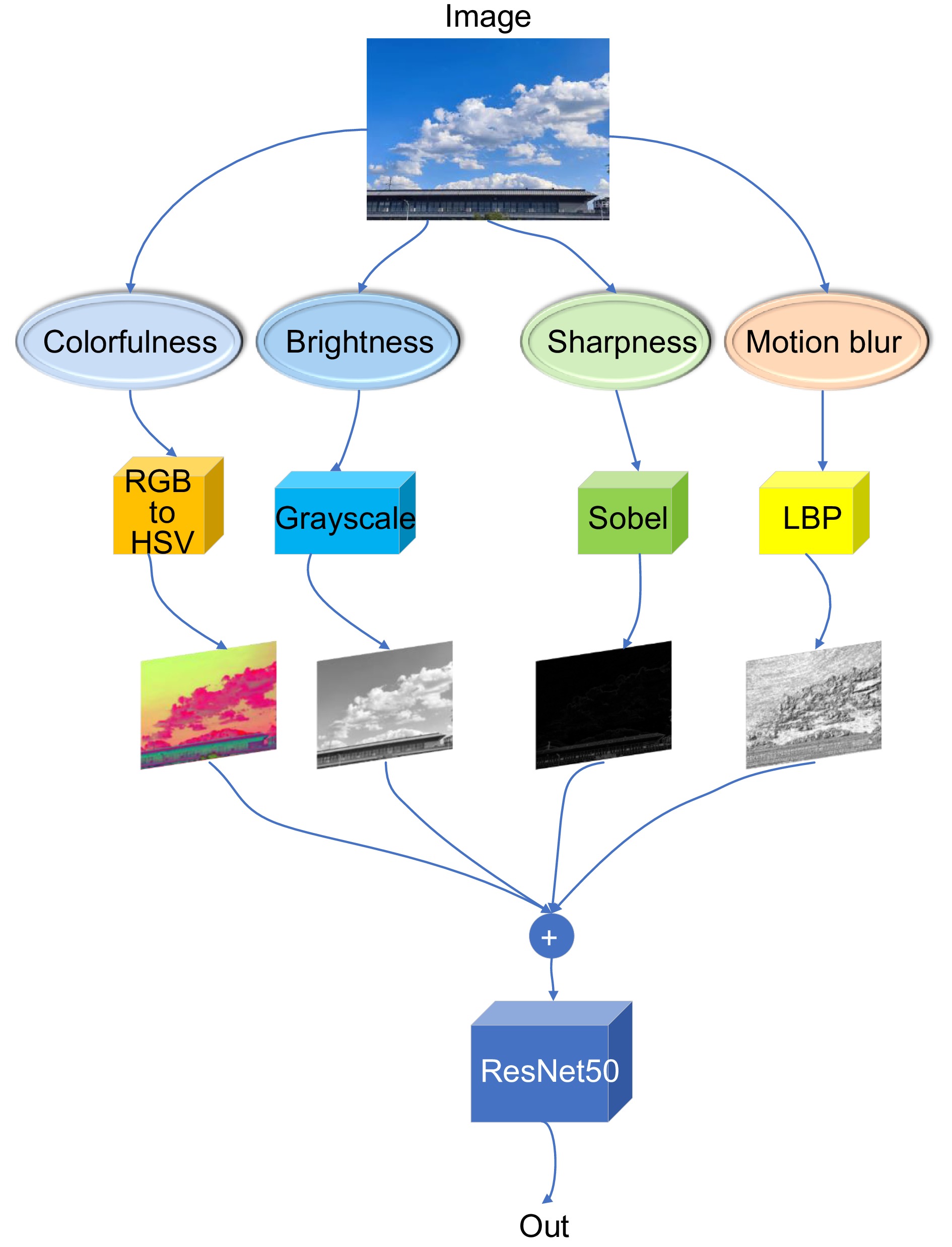
手工特征提取网络部分包括多种空间特征和颜色特征的提取:亮度特征、彩色特征、锐度特征和运动模糊特征。这些特征不仅提供了关于图像内容的信息,而且还涵盖了与图像质量相关的信息。将上述提取的手工特征送入ResNet50。
2.1 手工特征提取
在本文中,手工特征提取部分符合人眼视觉感知的特点,它是提高图像质量预测精确度的重要组成部分。手工特征的提取如图2所示。本文使用多种图像处理技术从原始图像中提取关键信息,这些信息包括彩色、亮度、锐度以及与智能手机拍摄图像质量紧密相关的运动模糊。此外,这些特征的选择和处理方式都考虑了人眼视觉感知的特性,以确保评价结果符合人眼对图像质量的真实感受。这些图像特征输入到ResNet50中,进行更深入的分析和处理。
2.1.1 彩色特征的提取
当RGB空间转换到HSV空间时,需要将红、绿、蓝三种彩色通道的数值转换为色调 (hue, H)、饱和度 (saturation, S)、亮度[13] (value, V)这三个数值[14]。HSV模型更贴近人眼对彩色的感知特点,使得彩色的处理和分析更加直观和有效。使用R、G、B分别表示红、绿、蓝通道的数值 (通常归一化到0到1之间)。在进行转换时,首先计算R、G、B这三个通道的最大值 (Max)和最小值 (Min),然后计算色调,它的计算相对复杂,需要根据最大值来确定。色调的计算分为三种情况,如式(1)所示:
如果${{Max}} = {{Min}}$,色调定义为0。饱和度的计算与最大值有关联,如果最大值为0 (图像完全为黑色),饱和度定义为0;否则,饱和度的计算如式 (2)所示:
亮度等于R、G、B的最大值。
2.1.2 亮度特征的提取
为了研究亮度对图像质量的影响,需要进行灰度值的转换。灰度值是所有彩色成分的加权平均,每个像素点的亮度信息用0到255之间的数值表示。这种方法考虑了人眼对不同彩色敏感度的差异,并对不同的彩色使用不同的权重,使用的公式[15]如式(3)所示:
其中:${G_{\mathrm{r}}}$表示灰度,R、G、B分别代表红色、绿色和蓝色通道的数值。式(3)可以确保图像在转换为灰度图时,能够保持人眼视觉的亮度感知特点,同时反映了人眼视觉对不同彩色的敏感度。由于人眼对绿色的敏感度最高,对蓝色的敏感度最低,所以式(3)中绿色通道的权重最大,蓝色通道的权重最小。式(3)广泛应用于图像处理和计算机视觉领域,使用这个公式获得的灰度图像,在视觉上更接近原始彩色图像的亮度特点。
2.1.3 锐度特征的提取
其中:G表示边缘的强度值,${G_x}$和${G_y}$分别代表水平方向和垂直方向上的梯度幅度值。使用这种方式得到的边缘强度图揭示了图像中所有边缘成分的位置及其强度。
图像锐度受多个因素的影响,例如对焦的准确性和摄影的质量等。边缘是人眼视觉系统处理图像的关键元素,因为它们帮助大脑解释物体的形状、大小和空间位置。锐度较高的图像具有更加明显的边缘,这种边缘能够帮助人眼视觉系统更快地识别和处理图像的内容。
Sobel算子使用图像在水平方向和垂直方向上的梯度幅度值来计算边缘的强度值。它利用两个尺寸为$3 \times 3$的卷积核分别对图像进行水平方向和垂直方向的卷积操作,计算出每个像素的梯度幅度值[16],从而得到每个像素的边缘强度值,如式(4)所示:
2.1.4 运动模糊特征的提取
局部二值模式 (Local binary patterns, LBP)专注于图像的局部结构,而运动模糊对图像的局部结构有着显著的影响。使用LBP分析图像局部结构的改变,能够帮助研究人员了解模糊对图像局部特征产生的影响。LBP操作首先定义一个以某个像素为中心的圆形邻域,圆周上均匀分布有P个邻域像素,其半径为Ro。然后,将每个邻域像素的灰度值与中心像素的灰度值进行比较。如果邻域像素的灰度值大于或等于中心像素的灰度值,则该邻域像素的比较结果为1;否则为0。每个中心像素都会生成一个P位的二进制数。最后,把这个二进制数转换成十进制数,作为该中心像素的LBP值[17]。LBP特征的计算如式 (5)所示:
其中:$ LBP_{P,R_{\mathrm{o}}} $表示得到的LBP值;${g_{\mathrm{c}}}$表示中心像素的灰度值;${g_p}$表示第p个邻域像素的灰度值;P表示邻域内的像素数量;Ro表示圆形邻域的半径;$s\left ( x \right)$表示一个阶跃函数,如式 (6)所示:
2.1.5 ResNet50
本文在使用ResNet50提取特征时,只使用其卷积层和池化层,没有使用最后的全连接层和输出层,ResNet50的网络结构如图3所示。本文在对智能手机拍摄的图像进行质量评价时,手工提取的特征与智能手机拍摄图像的质量之间存在非线性映射关系。ResNet50中的深层神经网络可以学习这种非线性映射关系,而简单地把手工特征进行组合无法做到这一点。ResNet50的加入可以作为一座桥梁,将手工提取的低级特征转化为抽象程度更高的特征。ResNet50得到的深度学习特征可以进一步提取手工特征中的信息,从而提供更加丰富的图像质量信息,这些信息包含了手工特征没有包含的图像质量因素。从特征结构的角度来看,手工特征从原始图像直接提取,而深度学习模型可以提供从不同网络层提取的特征。经过ResNet50处理后的特征可以更好地与Swin-AK Transformer中提取的特征进行结合,从而增强最终质量特征的描述能力。
2.2 Swin-AK Transformer
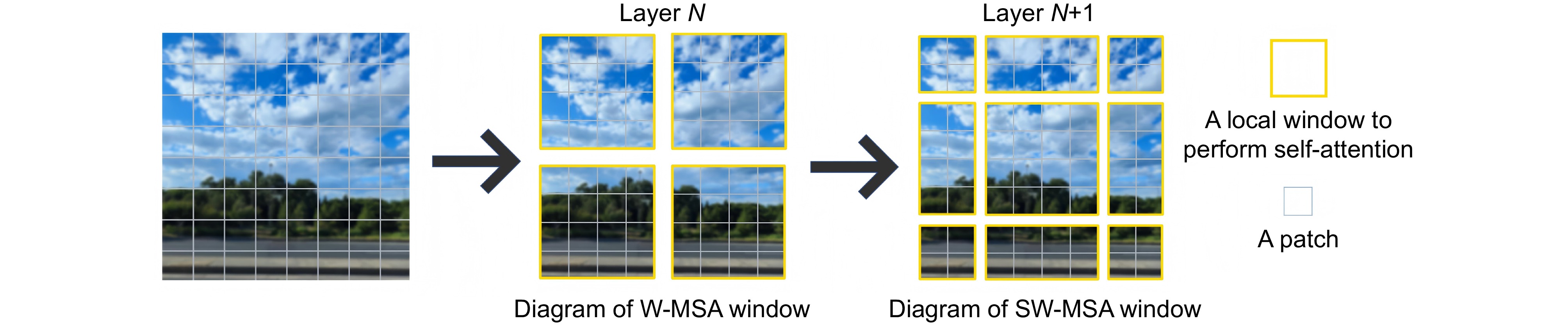
在图4中,黄色框表示用于计算自注意力的滑动窗口,灰色框表示一个图像块。第 N 层将图像划分为不重叠的局部窗口 (黄色边框),在每个窗口内计算自注意力以提取局部特征,把这种操作得到的自注意力称为窗口多头自注意力 (window multihead self-attention, W-MSA)。第 N+1 层进行滑动窗口操作 (即窗口边界的移动)实现跨窗口连接,逐步整合全局信息,并在重新分配的窗口内计算自注意力,把这种操作得到的自注意力称为滑动窗口多头自注意力 (shifted window multi head self attention, SW-MSA)。交替进行注意力的计算和滑动窗口操作,模型在保持计算复杂度的同时,能够逐步融合局部与全局信息,从而适应高分辨率图像的处理需求。每个窗口进行展平操作,用于后续的多头自注意力机制,如式(7)所示。
本文提出的Swin-AK Transformer的主要结构如图5所示,它包括图像分块 (patch partition)、线性嵌入 (linear embedding)以及多个包含滑动窗口自注意力机制的Swin-AK块 (Swin-AK block)。在每个阶段 (Stage 1至Stage 4)之间,使用图像块合并 (patch merging)操作减少特征图的分辨率,同时增加通道的数量。
对滑动后的特征图重新划分窗口,并使用多头自注意力机制,如式(10)所示。
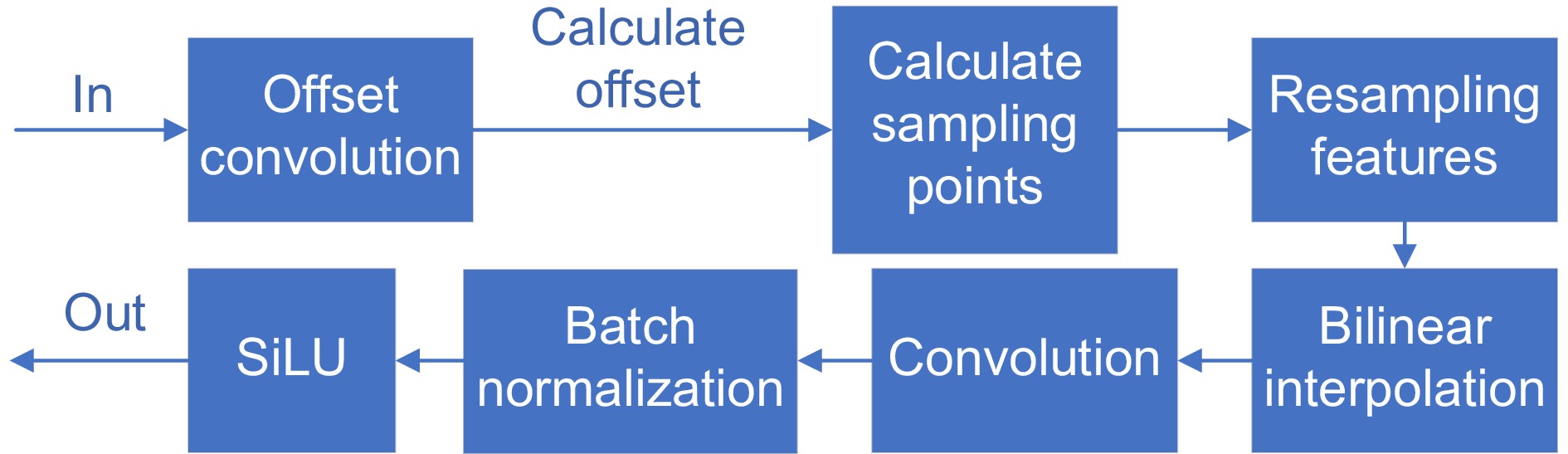
AKConv是Swin-AK blocks中的关键组成部分,它显著增强了特征的理解能力和细节捕捉能力,它的结构如图7所示。AKConv使用局部卷积操作,并结合偏移卷积来调整采样点位置,从而更有效地捕捉图像中的细节和纹理信息。AKConv模块首先使用一个卷积层计算出偏移量,并利用偏移量对输入特征进行重新采样;然后,使用双线性插值把来自四个相邻点的特征值结合起来;接着,使用卷积层对重新采样后的特征图进行卷积操作;最后使用批归一化操作和Sigmoid门控线性单元 (sigmoid gated linear unit, SiLU)激活函数进一步提升特征的表达能力。AKConv能够更好地提取复杂的图像特征,从而提高了本文方法对图像质量的评价能力。
![图 4 Swin Transformer的滑动窗口操作示意图]() 图 4
图 4Swin Transformer的滑动窗口操作示意图
Figure 4.Diagram of the sliding window operation in Swin Transformer
为实现跨窗口的信息交互,Swin-AK Transformer在相邻层中对窗口的位置进行偏移操作,将窗口在水平方向和垂直方向上分别移动$\left\lfloor {\dfrac{M}{2}} \right\rfloor $个单位 ($\left\lfloor {} \right\rfloor $表示向下取整符号,取不大于$\dfrac{M}{2}$的最大整数),其中窗口的尺寸为$M \times M$,如式(9)所示。
其中:X表示输入特征图;${X_{{\mathrm{shift}}}}$表示滑动后的特征图;shift[·]表示窗口的滑动操作。
将滑动窗口后的输出结果和原窗口的输出结果进行合并,形成最终的特征图。
其中:${X_{{\text{shift,}}i}}$表示第i个滑动后的窗口;H表示窗口的数量。
其中:Q表示查询向量;K表示键向量;V表示值向量;${{\boldsymbol{W}}_{\rm{Q}}}$、${{\boldsymbol{W}}_{\rm{K}}}$、${{\boldsymbol{W}}_{\rm{V}}}$表示权重矩阵。
其中:${X_i}$为尚未展平的第i个窗口;维度为$ {R^{{M^2} \times C}} $;窗口的空间尺寸为${M^2}$;C为通道的数量;$ X_i^{\mathrm{p}} $为展平后的第i个窗口。对展平后的窗口$ X_i^{\mathrm{p}} $,使用线性变换得到查询向量、键向量和值向量,如式(8)所示。
Swin Transformer[18]使用了滑动窗口自注意力机制,此机制利用不重叠的局部窗口自注意力操作有效地降低了全局自注意力机制的计算复杂度,从而能够在资源受限的情况下处理更大的图像,并保持较高的计算效率。它侧重于全局信息的处理,而忽略了局部特征产生的影响。然而,由于滑动窗口具有固定的尺寸,Swin Transformer在处理局部特征和复杂的纹理时存在不足,特别是针对图像中的细致结构[19],其固定窗口无法适应不同尺度的特征。为了解决这个问题,本文提出了Swin-AK Transformer,在Swin Transformer中使用可动态改变卷积核尺寸的卷积操作。AKConv根据图像的局部内容自适应地调整卷积核的尺寸,使模型能够更灵活地处理不同尺度的图像特征。这一改进显著增强了网络对复杂局部细节的捕捉能力,尤其是在处理具有精细的纹理和高度复杂的图像中表现出更优异的性能。Swin-AK Transformer不仅保留了Swin Transformer在全局上下文建模中的优势,还显著提升了对细节特征的理解能力,在图像质量评价任务中表现出更高的精确性和鲁棒性。
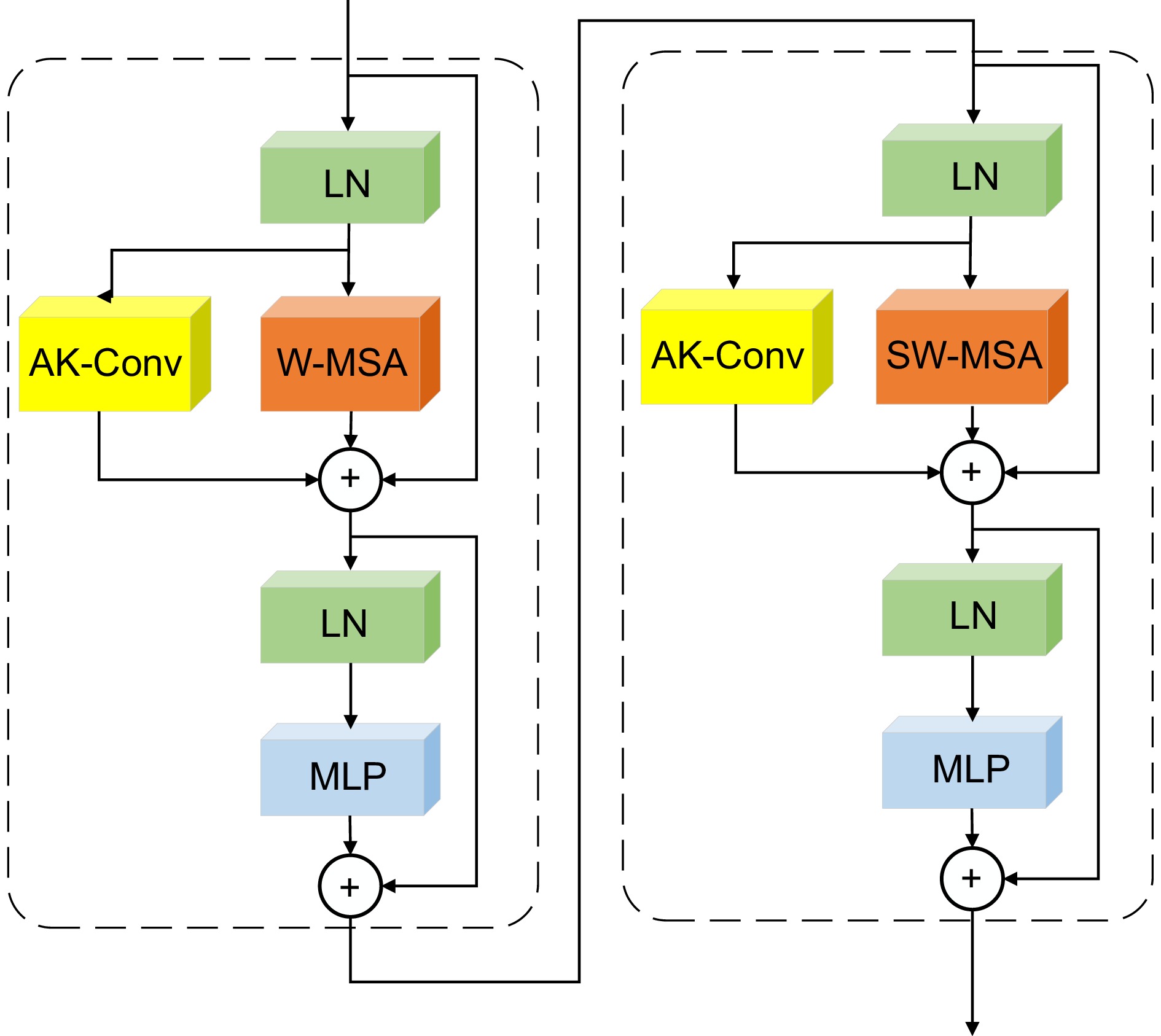
Swin-AK blocks的结构如图6所示。首先,输入的特征经过层归一化 (layer normalizaiton, LN)。然后,使用AKConv和 W-MSA并行处理。AKConv进行动态卷积操作,W-MSA则使用划分窗口计算局部注意力机制,两者输出的结果融合在一起,融合后的特征使用LN和多层感知器 (multilayer perceptron, MLP)进行处理。最后,使用SW-MSA代替W-MSA去重复前面的操作。和W-MSA相比,SW-MSA使用了滑动窗口机制,所以它能够更好地提高模型的全局感知能力和特征提取能力。该结构使用AK-Conv和W-MSA的并行工作,增强了特征提取的多样性和鲁棒性,有效提高了图像特征的表示能力。
在Swin Transformer中,首先将图像划分为互不重叠的多个窗口,如图4所示;然后,在每个窗口内独立计算自注意力,从而显著降低了计算复杂度。
接着,计算查询向量和键向量之间的点积,并使用 Softmax 函数进行归一化操作。最后,将多个头的结果进行拼接,并使用线性变换得到最终的输出结果。
2.3 双交叉注意力特征融合网络
![图 8 双交叉注意力特征融合模块的结构示意图]() 图 8
图 8双交叉注意力特征融合模块的结构示意图
Figure 8.Structure diagram of the dual attention cross fusion module
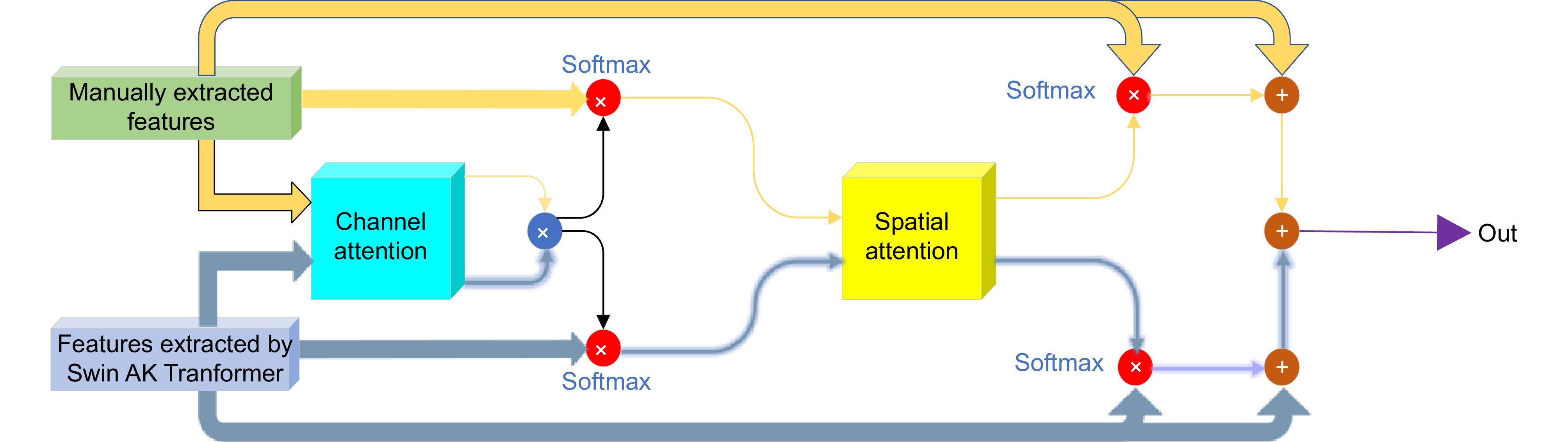
本文提出的双交叉注意力特征融合网络 (dual attention cross fusion, DACF)使用了通道注意力机制和空间注意力机制,将手工提取的特征和Swin-AK Transformer提取的特征融合,显著提升了模型对关键信息的捕获能力。
此外,DACF模块的自适应调整能力使其能够根据图像的内容和特性灵活处理不同类型的图像。该机制在多种数据集上的高效表现表明,适应智能手机拍摄图像中多样化的失真。这种灵活性和自适应性显著提高了本文方法在智能手机图像质量评价中的泛化能力。
DACF模块对图像特征的通道和空间维度的双重优化,保证了特征融合过程的全面性。结合通道和空间的双重注意力机制,不仅增强了模型对全局信息的把握,也提升了细节特征的捕捉能力。这种多层次的特征融合策略更加符合人眼的主观感知特性,确保了智能手机拍摄图像质量评价的高准确性和鲁棒性。
通道注意力模块的结构如图9所示。在通道注意力模块中,首先分别使用最大池化操作和平均池化操作提取该模块输入信号的全局信息;然后,使用MLP进行处理,生成通道权重,用于重新加权输入特征,从而突出重要的通道特征;最后,把加权后的两个特征组合在一起,作为通道注意力模块的输出结果。
DACF模块的创新在于将上述两种注意力机制有机结合,使得融合后的特征不仅在通道维度上得到优化,还在空间维度上进行了精细调整,从而实现了多维度的特征感知。这种融合方式有效提高了模型对图像整体和局部细节的敏感度,确保模型能够兼顾全局结构和局部信息。使用这种双重注意力机制,DACF模块能够更好地捕捉图像中的复杂信息,提升特征表达的鲁棒性和准确性。
双交叉注意力模块的结构如图8所示。其输入的特征由手工提取的特征与Swin-AK Transformer提取的特征组成。首先,通道注意力模块分别处理这两部分特征,通过Softmax函数进行初步融合,之后将融合后的特征输入空间注意力模块进行进一步优化。最终,优化后的特征与原始输入特征再次融合,从而生成更加全面的特征表示。
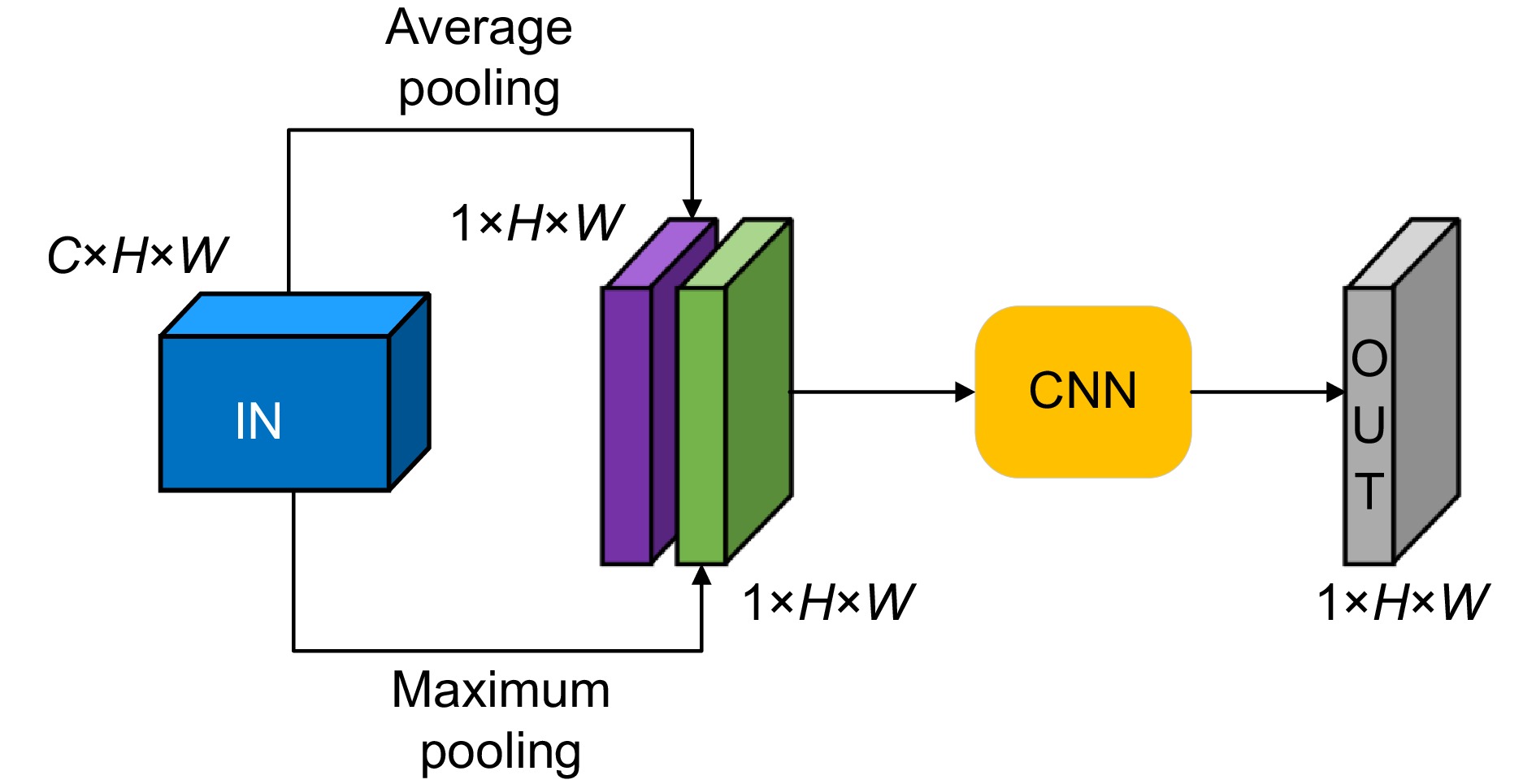
在DACF模块中,通道注意力机制专注于优化特征图的不同通道响应。该机制使用自适应地分配各通道的权重,抑制不重要的特征,增强对关键通道的关注,从而确保模型能够从多个通道中提取具有较强判别力的特征。与此同时,空间注意力机制则侧重于识别图像中的重要区域。该机制通过提取局部空间信息,优化特征图在空间维度上的分布。它能够有效过滤掉背景噪声,同时保留关键的结构和细节信息。
空间注意力模块的结构如图10所示。空间注意力模块首先使用平均池化操作和最大池化操作;然后使用CNN提取特征的空间信息;最后,把CNN的结果作为空间注意力模块的输出结果。
3. 实验及结果分析
3.1 数据集及评价指标
SPAQ[7] (Smartphone photography attribute and quality)数据集是一个专门用于评价智能手机摄影质量的大规模图像数据集。该数据集包含了11125张由66款智能手机拍摄的照片,每张照片包含主观评分、亮度评分、锐度评分和色彩度评分等。SPAQ数据集的主观评分实验由超过600名受试者参与。
PLCC是一种衡量两个向量线性相关性的统计度量,它反映了图像的质量预测分数与主观质量评分之间的线性关系。同时使用这两个指标可以有效地评价图像质量评价模型的预测性能,如式(12)所示。
本文采用LIVE-C数据集和SPAQ数据集进行实验。
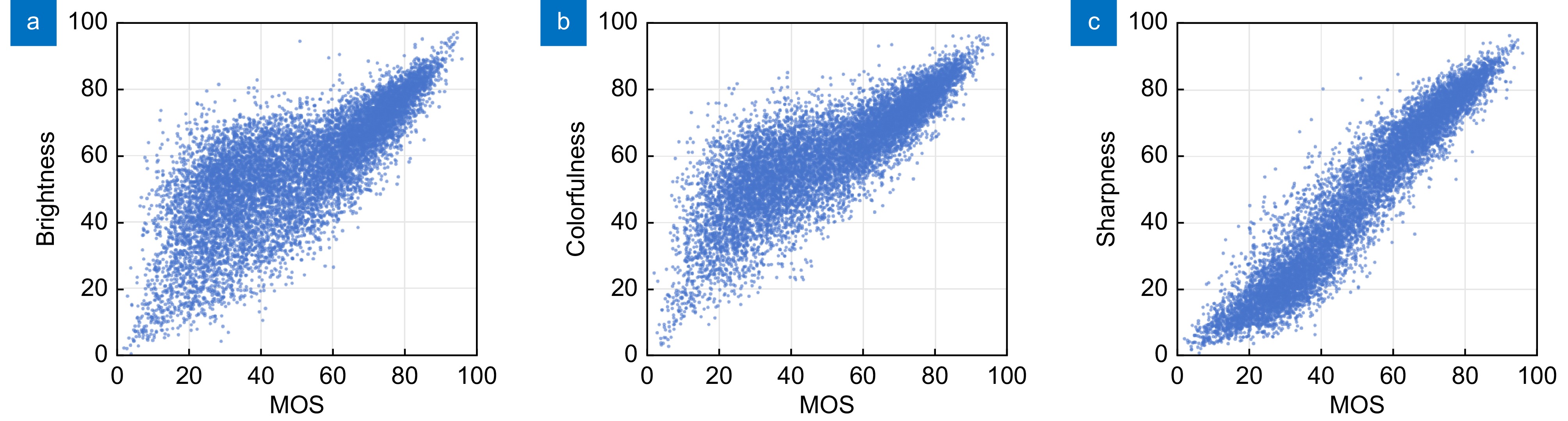
在SPAQ数据集中,图像的三种属性评分与整体主观质量评分之间的散点图如图11所示。通过分析SPAQ数据集的亮度评分、锐度评分和色彩度评分,可以发现这三种图像属性评分均与图像的主观质量评分存在一定的正相关关系。亮度评分较高的图像往往具有较高的质量评分,锐度评分与质量评分之间的相关性最为显著,色彩度评分也表现出明显的正相关趋势。然而,并不是所有数据点都严格遵循这一关系,这表明还有其它因素影响图像质量评分。此外,对亮度、锐度和色彩度的评分是为了更好地模拟人眼的视觉感知,从而提供更全面的图像质量评价。
LIVE-C[20] (LIVE challenge)数据集包含1170个图像,各种移动摄像设备在不同条件下进行拍摄而得到了这些图像。这些图像在获取过程中受到了多种失真类型的影响。LIVE-C数据集中的图像由超过8100名参与者在严格监控的众包研究中进行评分。
式中:$ {s_i} $、$ {p_i} $分别表示第i幅图像的主观质量分数、客观质量分数;$ \bar s $、$ \bar p $分别表示$ {s_i} $、$ {p_i} $的平均值。
![图 11 SPAQ数据集中图像属性评分与整体主观质量评分之间的散点图。(a)亮度;(b)色彩度;(c)锐度]() 图 11
图 11SPAQ数据集中图像属性评分与整体主观质量评分之间的散点图。(a)亮度;(b)色彩度;(c)锐度
Figure 11.Scatter plot of image attribute scores versus overall subjective quality scores in the SPAQ. (a) Brightness; (b) Colorfulness; (c) Sharpness
本文采用的评价指标是斯皮尔曼等级排序相关系数 (Spearman rank order correlation coefficient, SROCC)和皮尔森线性相关系数 (Pearson linear correlation coefficient, PLCC)。SROCC是一种衡量两个向量排序一致性的非参数统计度量,它反映了图像的质量预测分数与主观质量评分之间的排序相关性,如式(11)所示。
式中:${{\boldsymbol{x}}_i}$、${{\boldsymbol{y}}_i}$分别表示主观评价向量、客观评价向量分别按相同顺序 (由小到大或由大到小)排序后,对于第i个成绩在各自序列中的序号;Nt表示图像的数量。
3.2 散点图分析
在LIVE-C数据集中,散点数量较少,散点的分布较为稀疏。而在SPAQ数据集中,散点的数量多,散点分的布更为密集,显示出更为明显的线性趋势。这表明在SPAQ数据集上,本文方法的预测性能更加稳定和准确。
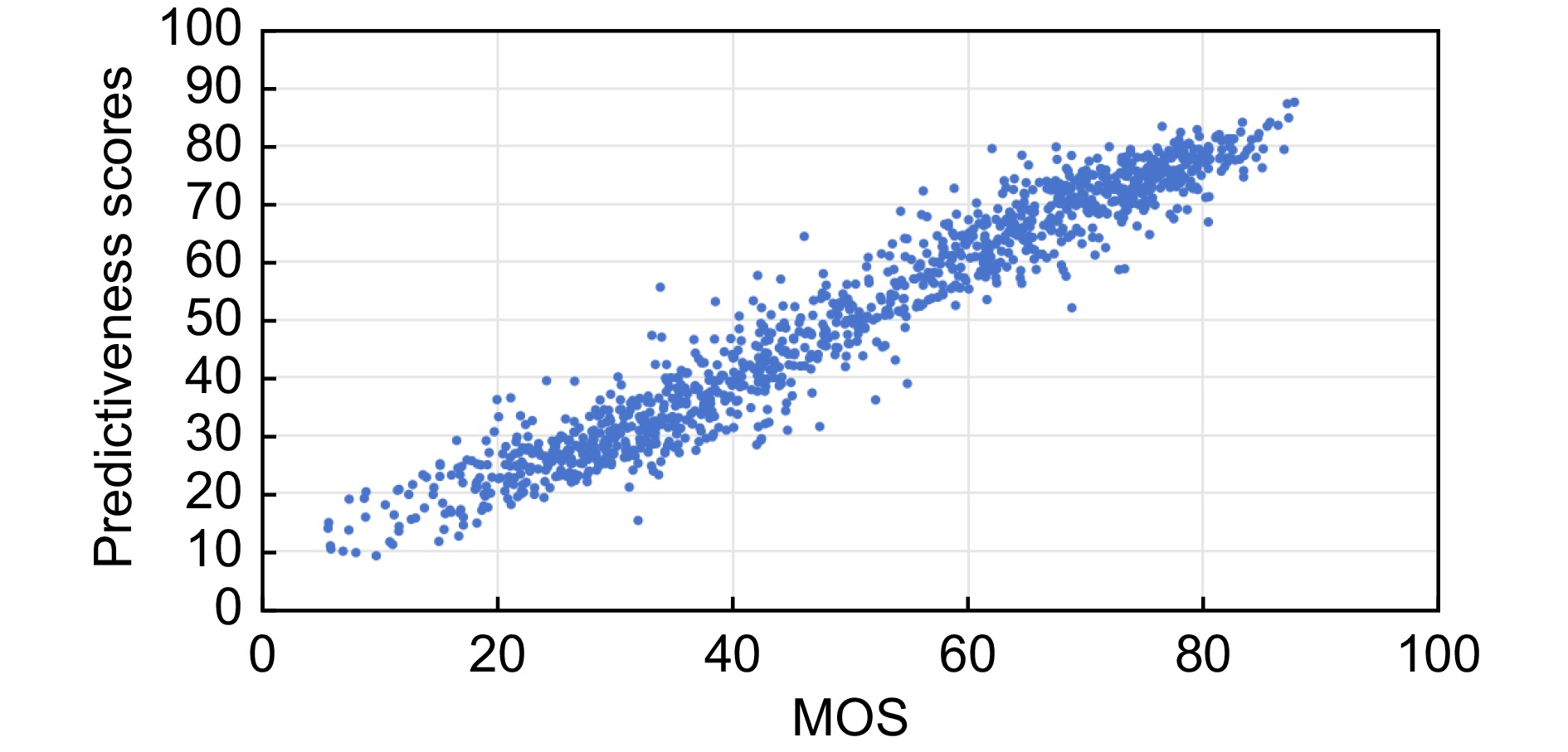
在本文的实验中,随机选取了LIVE-C和SPAQ两个数据集中的80%和20%作为训练集和测试集。实验使用Python 3.11.7语言,并使用Pytorch2.2.1深度学习框架进行编译和运行。CPU为Intel Core i5-6500,计算机内存的容量为16.0 GB,GPU为NVIDIA GTX 4090Ti,其显存的容量为24 GB。图12和图13分别展示了在LIVE-C和SPAQ数据集上本文方法的质量预测分数与主观质量评分之间的散点图。从这两张图可以看出,这两张图均显示出主观质量评分值 (mean opinion score, MOS)与本文方法的质量预测值具有正相关的关系。
3.3 对比实验
Comparison of the proposed method with other methods on the SPAQ dataset
本文方法在SPAQ数据集上与其它方法的对比
Methods PLCC SROCC BLINDS-II[21] 0.539 0.478 DIIVINE[22] 0.603 0.596 BRISQUE[23] 0.817 0.828 CORNIA[24] 0.724 0.709 IL-NIQE[25] 0.704 0.695 HOSA[26] 0.824 0.817 DIQaM-NR[27] 0.836 0.824 WaDIQaM-NR[27] 0.843 0.821 TS-CNN[28] 0.811 0.801 TReS[29] 0.911 0.902 DB-CNN[30] 0.913 0.909 HyperIQA[31] 0.919 0.916 CaHDC[32] 0.841 0.833 ResNet50[7] 0.909 0.908 MT-A[7] 0.916 0.916 MUSIQ[2] 0.921 0.917 DACNN[33] 0.921 0.915 Re-IQA[34] 0.925 0.918 DEIQT[35] 0.923 0.919 LoDa[36] 0.928 0.925 Ours 0.932 0.929 为了验证本文方法的性能,将本文方法与16种无参考质量评价方法进行比较,其中6种方法是基于手工特征提取的方法,它们分别是BLINDS-II[21]、DIIVINE[22]、BRISQUE[23]、CORNIA[24]、IL-NIQE[25]和HOSA[26];9种方法是基于深度学习的方法,它们分别是DIQaM-NR[27]、WaDIQaM-NR[27]、TS-CNN[28]、TReS[29]、DB-CNN[30]、HyperIQA[31]、CaHDC[32]、MT-A[7]、MUSIQ[2]、DACNN[33]、Re-IQA[34]、DEIQT[35]和LoDa[36]。在SPAQ和LIVE-C数据集上,本文方法与其它方法的对比分别如表1和表2所示。
表2给出了本文方法在LIVE-C数据集上与其它方法的SROCC和PLCC对比结果。从表2中可以看出,本文方法同样在两个指标上均表现优异,PLCC的值和SROCC的值分别为0.885和0.865。这表明本文方法在不同数据集上具有较好的适应性和泛化能力,特别是与BLINDS-II、DIIVINE这两种传统的无参考质量评价方法相比,本文方法的PLCC和SROCC分别提高了0.388和0.409、0.328和0.352,这表明本文提出的本文方法在智能手机拍摄图像质量评价任务中具有显著优势。
表1给出了本文方法在SPAQ数据集上与其它方法的SROCC和PLCC对比结果。可以看到,本文方法在两个指标上均表现出色,PLCC的值和SROCC的值分别为0.932和0.929。这表明本文方法在预测图像质量方面具有更高的相关性和一致性,能够更准确地反映主观质量的评分。此外,本文的实验结果验证了本文提出的本文方法在智能手机拍摄图像质量评价任务中具有较好的稳健性和可靠性。
Comparison of the proposed method with other methods on the LIVE-C dataset
本文方法在LIVE-C数据集上与其它方法的对比
Methods PLCC SROCC BLINDS-II[21] 0.497 0.456 DIIVINE[22] 0.557 0.513 BRISQUE[23] 0.637 0.616 CORNIA[24] 0.659 0.617 IL-NIQE[25] 0.516 0.539 HOSA[26] 0.691 0.674 DIQaM-NR[27] 0.645 0.633 WaDIQaM-NR[27] 0.692 0.669 TS-CNN[28] 0.667 0.655 TReS[29] 0.877 0.846 DB-CNN[30] 0.859 0.852 HyperIQA[31] 0.870 0.855 CaHDC[32] 0.738 0.734 MUSIQ[2] 0.875 0.862 DACNN[33] 0.882 0.861 Re-IQA[34] 0.854 0.84 Ours 0.885 0.865 3.4 消融实验
![图 14 Swin Transformer和Swin-AK Transformer的注意力热力图对比]() 图 14
图 14Swin Transformer和Swin-AK Transformer的注意力热力图对比
Figure 14.Comparison of attention heatmaps between Swin Transformer and Swin-AK Transformer
Results of the ablation experiment
消融实验的结果
Model PLCC SROCC Swin Transformer 0.921 0.918 Swin-AK Transformer 0.923 0.920 Manual features+
Swin Transformer0.924 0.922 Manual features+
Swin-AK Transformer0.929 0.925 Ours 0.932 0.929 其次,将Swin Transformer模型和提取手工特征融合后,PLCC和SROCC的值提高到0.924和0.922;接着,当进一步将Swin-AK Transformer融合手工特征后,PLCC和SROCC分别增至0.929和0.925,这反映出手工特征对提升模型预测精度的重要性;最后,使用双交叉注意力特征融合网络将Swin-AK Transformer和手工特征融合后,本文方法在PLCC和SROCC上都表现出了最佳的性能,这表明本文提出的方法具有更好地细节捕捉能力,能够更好地符合人眼视觉感知的特点。
从表3可以看出,首先,基础的Swin Transformer模型在SPAQ数据集上的PLCC和SROCC分别为0.921和0.918;然后,Swin-AK Transformer模型的PLCC和SROCC分别提高到了0.923和0.920,Swin Transformer和Swin-AK Transformer的注意力热力图如图14所示。从图14可以看出,和Swin Transformer模型相比,Swin-AK Transformer模型显著增强了对局部特征的捕捉能力。
为了评价本文方法中的各个模块对此模型整体性能产生的影响,本文在SPAQ数据集上进行了一系列的消融实验,实验结果如表3所示。
3.5 图像分析实验
在LIVE-C数据集的测试集中,按照MOS值从小到大的顺序选取了8张图像,这些图像的MOS值、本文方法的质量预测值和MUSIQ[2]方法的质量预测值如图16所示。通过对比这些图像,可以看出本文方法在各种不同拍摄场景下的预测效果。从夜间的灯光展示、白天的户外活动,到风景和植物的拍摄,本文方法的质量预测值非常接近于实际的MOS值。即便在光照变化较大的场景下,例如夜景和逆光,本文方法依然能够提供接近实际评分的预测值。对于这8张图像,本文方法的MSE的值为61.95,明显低于MUSIQ[2]方法的MSE值249.45。但是,由于LIVE-C数据集的图像数据数量较少,导致预测值与实际值之间的差异略大于SPAQ数据集。总体而言,实验结果验证了本文方法在多样化拍摄条件下具有较好的鲁棒性,并表明其在不同环境下进行图像质量评价具有较好的可靠性和稳定性。
![图 15 SPAQ数据集中图像的MOS值与本文方法的质量预测值]() 图 15
图 15SPAQ数据集中图像的MOS值与本文方法的质量预测值
Figure 15.MOS values of images in the SPAQ dataset and the quality prediction values of the proposed method
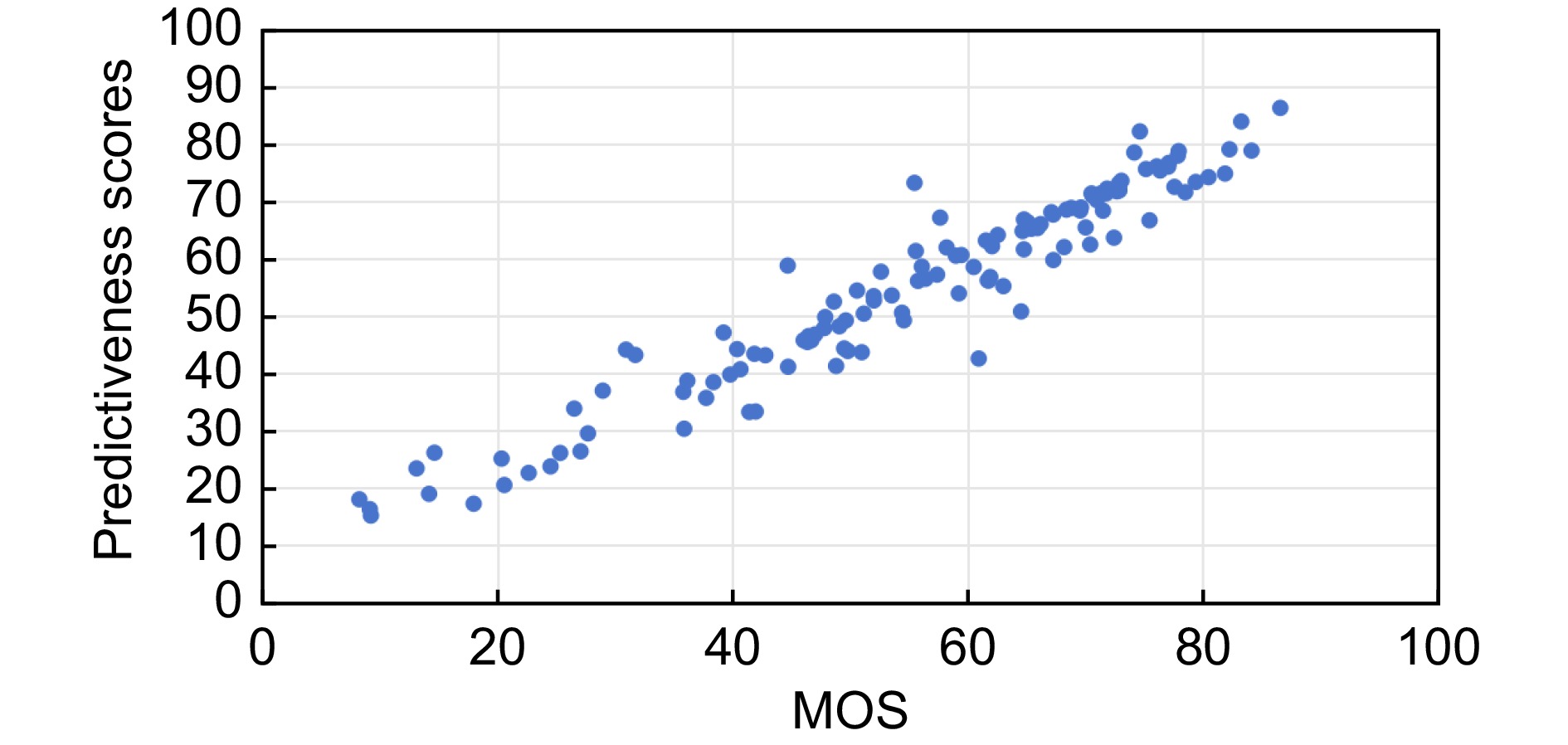
为了进一步验证本文方法的性能,本文在SPAQ数据集的测试集中按照MOS值从小到大的顺序选取了8张图像。对于这些图像,本文方法的质量预测值、MUSIQ[2]方法的质量预测值与MOS值如图15所示。从图15可以看出,本文方法的预测值相比于MUSIQ[2]方法的预测值能够更准确地反映图像的主观质量评分。无论是白天拍摄的城市景观、夜景、室内的食物照片,还是模糊的图像,本文方法的质量预测值均接近实际的MOS值。本文方法的均方误差 (mean squared error, MSE)值为14.02,远低于 MUSIQ[2]方法的MSE值226.83。这些结果表明,本文方法在不同类型图像上的表现更加稳定,能够较好地反映人类视觉对图像质量的感知特点。同时,本文方法对高质量和低质量图像的预测均表现出较高的精度,进一步验证了其在图像质量评估任务中的优越性能。
![图 16 LIVE-C数据集中图像的MOS值与本文方法的质量预测值]() 图 16
图 16LIVE-C数据集中图像的MOS值与本文方法的质量预测值
Figure 16.MOS values of images in the LIVE-C dataset and the quality prediction values of the proposed method
4. 结 论
本文针对目前已有的智能手机拍摄图像无参考质量评价算法存在的不足,提出了一种基于手工特征和Swin-AK Transformer双交叉注意力融合网络的智能手机拍摄图像质量评价方法。首先,本文根据人眼视觉感知的特性,提取影响图像质量的手工特征。为了学习手工特征和图像质量之间的非线性映射,本文在手工特征提取后加入了ResNet50,将手工提取的低级特征转化为更抽象的高级特征;然后,使用Swin-AK Transformer中的自注意力机制捕获图像的局部特征,增强了对局部空间信息的处理能力;最后,设计了双交叉注意力融合模块,把上述得到的两种特征进行融合,确保在融合过程中不仅关注图像的全局信息,还能精确地捕捉到图像中的细节变化。在SPAQ和LIVE-C数据集上的实验结果表明本文提出的方法能够精准地预测智能手机拍摄图像的质量,并符合人眼视觉感知的特点。
课题的后续研究将致力于智能手机拍摄图像的质量增强,使智能手机拍摄图像的质量接近甚至达到单反相机拍摄图像的质量。这包括提升图像的清晰度、色彩还原、细节表现和在各种拍摄条件下 (如低光、高动态范围等)的整体质量。这不仅能够为普通用户提供更高质量的拍摄体验,也为专业摄影和图像处理应用提供了更广泛的研究方向。
-
参考文献
[1] 鄢杰斌, 方玉明, 刘学林. 图像质量评价研究综述——从失真的角度[J]. 中国图象图形学报, 2022, 27 (5): 1430−1466.
DOI: 10.11834/jig.210790Yan J B, Fang Y M, Liu X L. The review of distortion-related image quality assessment[J]. J Image Graphics, 2022, 27 (5): 1430−1466.
DOI: 10.11834/jig.210790[2] Ke J J, Wang Q F, Wang Y L, et al. MUSIQ: multi-scale image quality transformer[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021: 5128–5137. https://doi.org/10.1109/ICCV48922.2021.00510.
[3] Varga D. No-reference image quality assessment using the statistics of global and local image features[J]. Electronics, 2023, 12 (7): 1615.
DOI: 10.3390/electronics12071615[4] Jain P, Shikkenawis G, Mitra S K. Natural scene statistics and CNN based parallel network for image quality assessment[C]//2021 IEEE International Conference on Image Processing (ICIP), 2021: 1394–1398. https://doi.org/10.1109/ICIP42928.2021.9506404.
展开 -
版权信息
版权属于中国科学院光电技术研究所,但文章内容可以在本网站免费下载,以及免费用于学习和科研工作 -
关于本文
引用本文
Citation:侯国鹏, 董武, 陆利坤, 周子镱, 马倩, 柏振, 郑晟辉. 基于Swin-AK Transformer的智能手机拍摄图像质量评价方法[J]. 光电工程, 2025, 52(1): 240264. DOI: 10.12086/oee.2025.240264Citation:Hou Guopeng, Dong Wu, Lu Likun, Zhou Ziyi, Ma Qian, Bai Zhen, Zheng Shenghui. Smartphone image quality assessment method based on Swin-AK Transformer. Opto-Electronic Engineering 52, 240264 (2025). DOI: 10.12086/oee.2025.240264导出引用出版历程
- 收稿日期 2024-11-10
- 修回日期 2024-12-22
- 录用日期 2024-12-22
- 刊出日期 2025-01-24
文章计量
访问数(563) PDF下载数(29)
- 563 访问数
- 29 下载数
 下载:
下载: