E-mail Alert
E-mail Alert RSS
RSS-
摘要
无人机航拍图像具有背景复杂、目标小且密集的特点。在无人机航拍图像检测中,存在小目标检测精度低和模型参数量大的问题。因此,提出基于超图计算的多尺度特征高效传递小目标检测算法。首先,设计高效传递多尺度特征金字塔网络作为颈部网络,在中间层融合多层特征,并将其向相邻各层直接传递,有效缓解传递路径冗长导致的信息丢失问题。另外,特征融合环节借助超图对高阶特征进行建模,从而增强模型的非线性表达能力。其次,设计轻量化动态任务引导检测头,借助共享机制在参数量较少的情况下,有效解决传统解耦头中分类与定位任务空间不一致导致检测目标不准确的问题。最后,基于层自适应幅度的剪枝轻量化模型,进一步减小模型体积。实验结果表明,此算法在VisDrone2019数据集上表现出比其他架构更优越的性能,精度mAP0.5和参数量分别达到了42.4%和4.8 M,与基准YOLOv8相比参数量降低了54.7%,该模型实现检测性能与资源耗费之间的良好平衡。
Abstract
UAV aerial images have the characteristics of complex background, small and dense targets. Aiming at the problems of low precision and a large number of model parameters in UAV aerial image detection, an efficient multi-scale feature transfer small target detection algorithm based on hypergraph computation is proposed. Firstly, a multi-scale feature pyramid network is designed as a neck network to effectively reduce the problem of information loss caused by lengthy transmission paths by fusing multi-layer features in the middle layer and transmitting them directly to adjacent layers. In addition, the feature fusion process uses hypergraphs to model higher-order features, improving the nonlinear representation ability of the model. Secondly, a lightweight dynamic task-guided detection head is designed to effectively solve the problem of inaccurate detection targets caused by inconsistent classification and positioning task space in the traditional decoupling head with a small number of parameters through sharing mechanism. Finally, the pruning lightweight model based on layer adaptive amplitude is used to further reduce the model volume. The experimental results show that this algorithm has better performance than other architectures on VisDrone2019 dataset, with the accuracy mAP0.5 and parameter number reaching 42.4% and 4.8 M, respectively. Compared with the benchmark YOLOv8, the parameter number is reduced by 54.7%. The model achieves a good balance between detection performance and resource consumption.
-
1. 引 言
无人机具有体积小、隐蔽性好、操作简便等优势,在多领域广泛应用,然而,无人机航拍图像普遍存在背景复杂、目标尺寸小、分布稀疏不均等特点,导致目标检测精度低,且需依赖复杂、庞大的模型才能提升精度。在无人机航拍任务中面临着检测环境复杂多变以及模型规模受限的问题,研发高效、精准的目标检测方法至关重要。
目前,主流目标检测方法大体可分为两阶段算法(如R-CNN[1]系列、Mask R-CNN[2]、Cascade R-CNN[3])和一阶段算法(如YOLO[4]系列、SSD[5]、RetinaNet[6])。两阶段算法先生成候选区域再进行目标定位和分类,精度较高但计算成本大。相比之下,一阶段算法直接通过单一网络进行定位和分类,具有更高的实时性,更适合无人机航拍图像的目标检测需求。选择YOLOv8作为基础网络,并对其特征提取和表示能力进行优化,以提升小目标检测精度并降低模型复杂度。
YOLO框架的颈部模块[7-10]是融合高层语义信息和低层空间细节的关键组件,对增强模型在不同尺度下目标检测能力至关重要。然而,传统的特征金字塔网络FPN[11]仅考虑单向信息流,存在信息利用率不足的问题。尽管BiFPN[12]、PAFPN[13]等方法设计多路径融合方式,但计算成本较高,且对特征间的复杂交互关系建模能力有限。AFPN[14]、MAF-YOLO[15]、DAMO-YOLO[16]和Gold-YOLO[17]等方法虽然在一定程度上改进了特征融合策略,但仍未充分挖掘不同尺度、位置和空间特征之间复杂的非线性高阶信息交互。增强对高阶特征的感知可以帮助模型过滤掉背景中的干扰信息。超图[18-19]结构,通过其独特的超边连接多个节点的方式,能够有效地建模数据间的复杂交互关系,为更深入地理解和利用特征间的复杂交互关系提供了新的途径,且显著提升YOLO模型的目标检测性能。
在传统的解耦检测头中,目标检测任务被分解为两个独立的子任务:目标定位和目标分类。分类分支主要关注图像的中心区域,因为该区域通常包含丰富的语义信息,有利于目标类别的识别;回归分支则主要关注图像的边界区域,因为该区域包含关于目标位置的关键信息,有利于精确地定位目标边界框。然而,在这种解耦设计中,不同尺度的检测头分别进行卷积操作,导致模型参数利用效率低,且容易过拟合,并增加模型计算负担。为了解决这个问题,Liu等[20]提出了一种轻量级的解耦头,通过动态计算特定任务的重要区域来提高效率;StarDL-YOLO则在检测头中引入了共享卷积层(LSCD),显著降低了计算量[21]。这些方法在一定程度上实现了轻量化,但由于两个分支是并行且独立训练的,特征之间缺乏有效的交互,且可能存在空间信息不对齐的问题,最终导致预测结果中出现空间不一致性,例如分类分支可能准确地识别目标类别,但回归分支却由于空间信息错位而预测出不准确的边界框。
为进一步降低模型的复杂度,许多学者针对模型轻量化进行了研究。典型的轻量级网络包括 SqueezeNet[22]、ShuffleNet[23]、MobileNet[24]、EfficientNet[25]和GhostNet[26]。但由于轻量级网络结构过于简单,导致网络的特征提取与融合能力减弱,无法充分提取待检测目标的特征信息和位置信息。王舒梦等[27]提出了一种基于轻量化PartialConv卷积的模型轻量化方法。张佳承等[28]在颈部网络中引入了GSConv和slim-neck,有效减少了模型的参数数量。此外,也有研究[29-30]表明,通过合理的超参数调整和神经元剪枝技术,可以有效地去除对神经网络性能影响较小的神经元,从而降低模型参数数量和计算负担,提升模型效率。
因此,针对上述小目标检测中存在的问题,提出了一种基于超图计算的高效传递多尺度特征小目标检测算法(hypergraph computing-based efficient transmission multi-scale feature network, HETMNet),旨在使算法具有较高精准率的同时减少参数数量。主要贡献概述如下:
1)设计了一种通用的高效传递多尺度特征金字塔网络(efficient transmission multi-scale feature pyramid network, ETMFPN)作为颈部网络,实现了融合特征以最短路径向不同层级传递,极大促进了高低层特征的充分交换,有效减少了信息的损失。在融合阶段,设计了高阶自适应融合模块(high order adaptive fusion module, HOAF),不仅能够实现多尺度特征的自适应融合,而且通过引入超图计算,显著增强了模型对高阶特征的感知能力,有效抑制背景中的噪声,增强复杂背景下小目标检测能力。
2)设计了轻量化动态任务引导检测头(lightweight dynamic task guide detection head, LDTG-Head)。基于共享机制将不同层级的FPN语义信息通过相同的LDTG-Head,促进分类和定位任务的动态对齐,避免两个分支在预测中产生空间不一致的问题,并显著降低了参数量。
3)对改进模型采取基于层自适应幅度的剪枝(LAMP)[31] 方法进行剪枝,使得模型在保持性能的前提下有效减少模型参数量,便于模型进行轻量化部署。
2. 检测算法
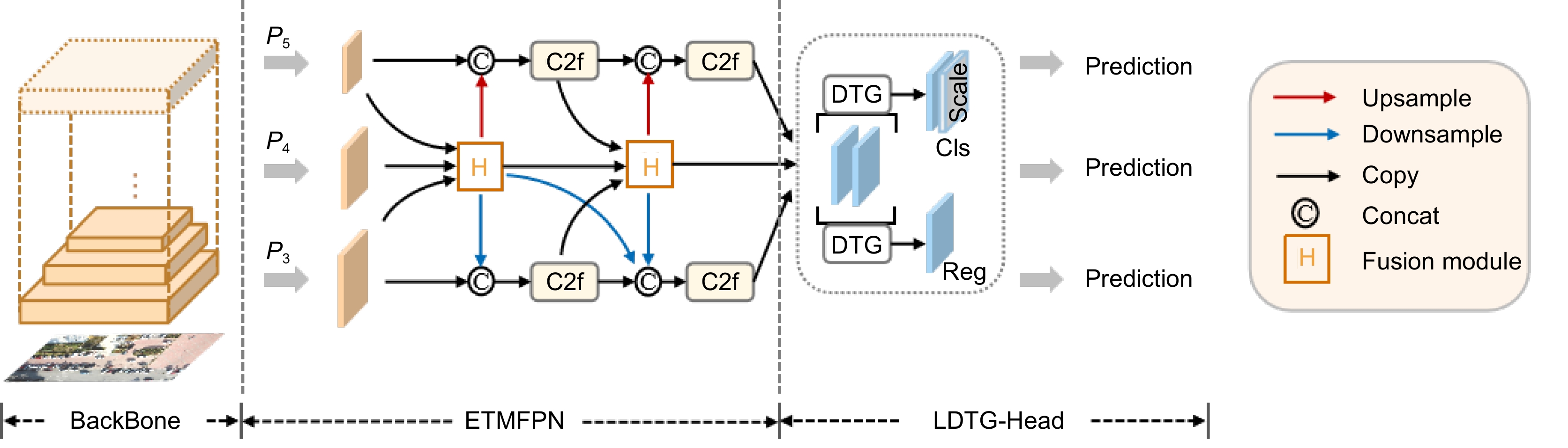
选用YOLOv8作为基础网络,设计一种基于超图计算的高效传递多尺度特征小目标检测算法(HETMNet)。HETMNet的模型体系结构由主干、ETMFPN颈部以及LDTG-Head 三个部分构成。HETMNet网络整体的架构如图1所示。首先,采用CSPDarkNet53作为主干进行特征提取。随后,将获取的特征图P3、P4、P5输入至ETMFPN中,以高阶特征为基础实现深、浅层特征信息自适应融合,整合跨层次和跨位置的信息并分散到其他各层中,使每一层都可以获得跨三种分辨率的多样化特征。最后,再经过LDTG-Head检测头,进行多尺度预测。
![图 1 基于超图计算的高效传递多尺度特征小目标检测算法]() 图 1
图 1基于超图计算的高效传递多尺度特征小目标检测算法
Figure 1.Efficient transfer multi-scale feature small target detection algorithm based on hypergraph computing
2.1 高效传递多尺度特征金字塔网络
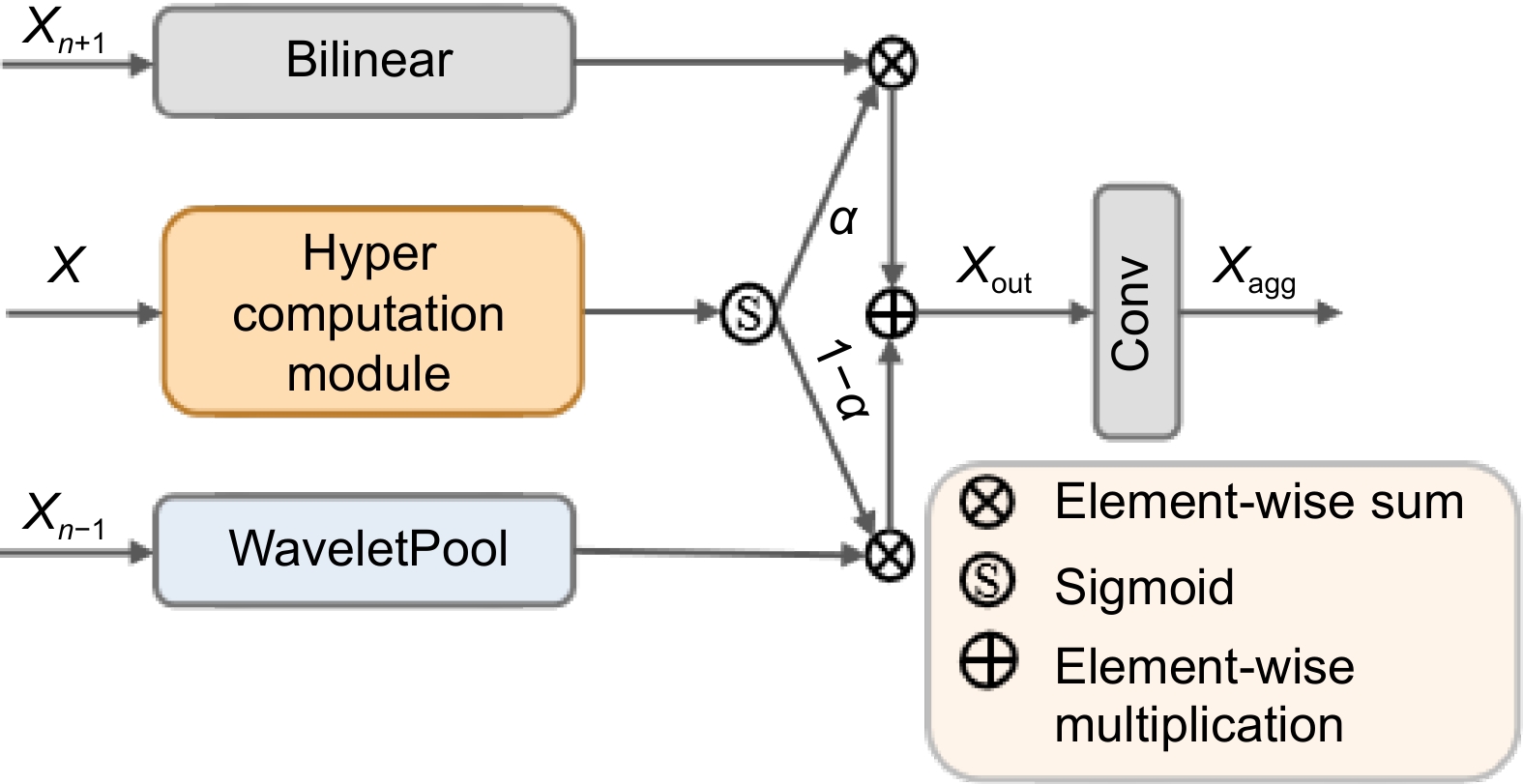
特征金字塔旨在从深度神经网络的主干中提取具有不同分辨率的特征,进而实现特征融合以增强模型的多尺度检测能力。然而,现有的特征金字塔网络由于特征传递路径冗长,普遍存在传递过程信息丢失的问题,模型对小目标的检测性能受到了限制。为了有效解决这些问题,设计了ETMFPN,如图1所示。在融合阶段,ETMFPN设计HOAF模块引入超图计算同时对浅层Pn−1和深层Pn+1进行多尺度特征融合,为网络提供细粒度的边缘细节信息和有助于目标分类的粗粒度语义信息,如图2所示。
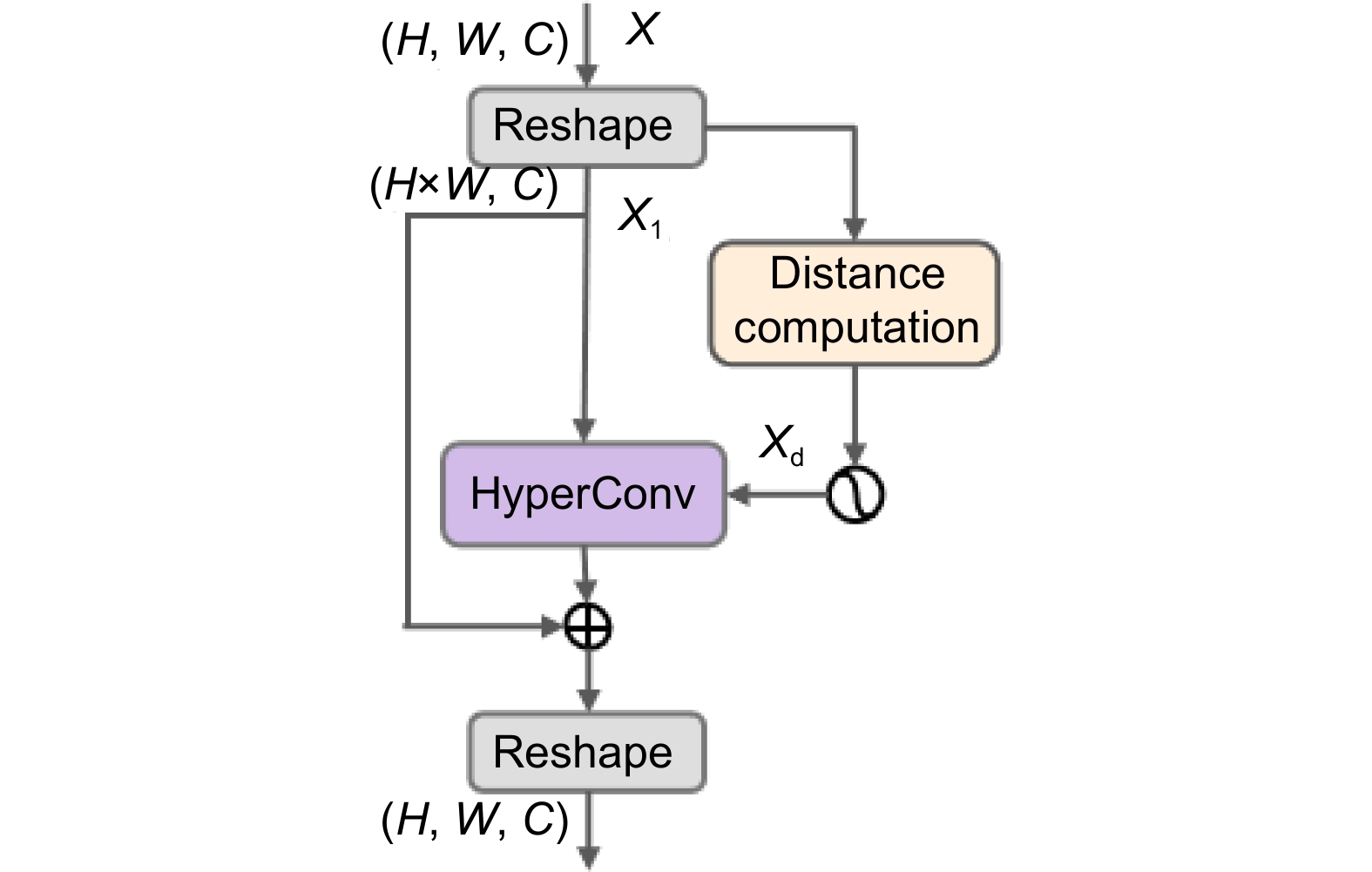
首先,深层特征Xn+1与浅层特征Xn−1分别通过双线性插值算法和小波池化与当前层特征X尺寸对齐,并通过1×1卷积调整通道数。普通池化在进行下采样时,往往会造成高频分量丢失,导致特征丢失或特征平滑,进而使图像细节信息受损。但小波池化能够把特征分解为高频子带与低频子带,通过对高频和低频子带进行加和操作,留存了低频分量里缺失的高频成分,有效减少浅层纹理细节特征丢失。然后,当前层特征X经过超图计算模块(图3),将P层特征的尺寸从(H, W, C)(H和W分别表示图像的高度和宽度,C表示通道数量)变换到(H×W, C)得到特征X1,根据X1计算特征与特征之间的距离,并以每个特征点为中心将小于距离阈值的特征点构建成超边,所有超边的集合则构成超图Xd,如图4所示,其中d表示距中心特征点的距离,ε表示距离阈值。
为了实现超图结构中高阶信息的有效传递,引入超图卷积[32]捕捉节点之间的高阶交互关系。将特征X1和超图Xd作为超图卷积的输入,利用均值聚合执行两阶段超图信息传递操作。第一阶段是从节点v到边e传递相邻节点与其边的关系;第二阶段则是从边e到节点v,将超边上的信息重新分配给对应的节点。获得丰富高阶特征后,为进一步增强原始特征的表达能力,将高阶特征与原始特征进行残差连接,对原始特征进行补充,引入更多的复杂语义信息,表达式为
\mathrm{\boldsymbol{\mathit{HC}}}\left(\boldsymbol{X},\boldsymbol{Y}\right)=\boldsymbol{X}+\boldsymbol{D}_{\mathrm{\mathit{v}}}^{-1}\boldsymbol{YD}_{\mathrm{\mathit{e}}}^{-1}\boldsymbol{\boldsymbol{Y}}^{\mathrm{T}}\boldsymbol{X}\theta\; , 式中:HC(·)表示超图卷积;X表示节点特征矩阵;Y表示超图的关联矩阵; \boldsymbol{D}_v^{ } 和 \boldsymbol{D}_e^{ } 分别表示顶点和超边的对角矩阵; \mathrm{\theta } 为可训练参数。
随后,将获得的高阶特征输入激活函数得到α,根据目标的尺寸自适应地选择合适的特征进行融合,挖掘了高阶特征与不同分辨率特征之间的非线性关系,从而促进了特征图内交叉位置的相互作用。如果α>0.5,则优先考虑细粒度局部特征,与低分辨率特征进行矩阵相乘,反之则强调上下文特征。之后,将不同分辨率的特征相加,经过 1\times 1 卷积进一步融合特征得到 {{X}}_{\mathrm{a}\mathrm{g}\mathrm{g}} ,构建更全面的特征表示。具体的表达式为
\alpha={\rm{Sigmoid}}\left({\boldsymbol{HC}}\left(X,X_{\mathrm{d}}\right)\right)\; , X_{\mathrm{out}}=\alpha\left(B\left(X_{n+1}\right)\right)+\left(1-\alpha\right)\mathrm{W}\mathrm{avePool}\left(X_{n-1}\right)\; , {{X}}_{{\mathrm{{a}{g}{g}}}}={\rm{Conv}}\left({{X}}_{{\mathrm{{o}{u}{t}}}}\right)\;, 式中:Sigmoid(·)为激活函数;B为双线性插值;WavePool(·)为小波池化;Conv(·)为卷积操作。
最后,在特征传递阶段,ETMFPN将融合后的特征直接向不同尺度相邻层直线传递,相比传统逐层传递特征的方式,有效缩短了传递的路径,减少了在传递过程中池化或卷积等操作导致的信息损失。通过ETMFPN的设计,使得颈部每一层都丰富了多尺度特征信息,有效提升了模型针对多尺度特征的检测效能。
2.2 轻量化动态任务引导检测头
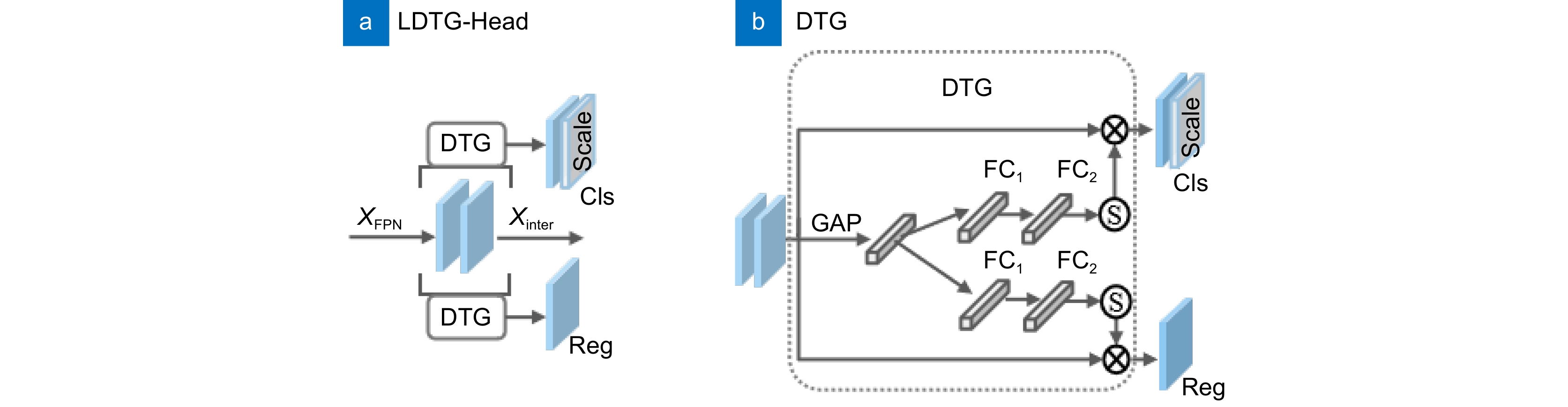
目前的单阶段算法中,每个检测头采用独立处理不同尺寸特征的方式,这不仅增加了模型计算量,而且检测头将任务分为分类和定位两个并行任务分别进行训练,这还可能导致特征图在空间维度不对齐的问题。为了解决上述问题,设计检测头LDTG-Head,其结构如图5所示。LDTG-Head运用共享权重,使颈部特征由同一个解耦头进行处理,在最大程度上降低了复杂度,也有效解决了检测头中分类与定位之间空间不对准的问题。LDTG-Head的具体运行过程如下:
![图 5 LDTG-Head和DTG模块结构示意图。(a) LDTG-Head;(b) DTG模块]() 图 5
图 5LDTG-Head和DTG模块结构示意图。(a) LDTG-Head;(b) DTG模块
Figure 5.Structure diagram of LDTG-Head and DTG module. (a) LDTG-Head; (b) DTG module
首先,该模块采用多层3×3分组卷积作为经过颈部的输出 X_{\mathrm{FPN}} 的特征提取器,以此来强化分类与定位任务之间的信息交互,从而得到特征 {{X}}_{\mathrm{i}\mathrm{n}\mathrm{t}\mathrm{e}\mathrm{r}} ,交互过程如式(5)和式(6)所示。分组卷积如图6所示,其原理是依据分组数(g)对通道进行划分,各分组分别执行卷积操作后再进行拼接,其中h1代表C2个filters的高度、w1代表C2个filters的宽度。普通卷积与分组卷积的参数量计算公式分别如式(7)和式(8)所示,从式中能够清晰地看出,运用分组卷积后,参数量仅为普通卷积参数量的1/g,这显著降低了计算复杂度和模型参数量。
![图 6 普通卷积与分组卷积对比。(a)普通卷积;(b)分组卷积]() 图 6
图 6普通卷积与分组卷积对比。(a)普通卷积;(b)分组卷积
Figure 6.Comparison between ordinary convolution and group convolution. (a) Ordinary convolution; (b) Group convolution
{{X}}_{{\mathrm{{i}{n}{t}{e}{r}}}\_1}={{{\mathrm{Group}}}\;{{\mathrm{Conv}}}}_{3\times 3}\left({{X}}_{{\mathrm{{F}{P}{N}}}}\right)\;, {{X}}_{{\mathrm{{i}{n}{t}{e}{r}}}}={\rm{Group}}\;{{\rm{Conv}}}_{3\times 3}\left({{X}}_{{{\mathrm{{i}{n}{t}{e}{r}}}\_1}}\right) \;, 式中: {\mathrm{G}\mathrm{r}\mathrm{o}\mathrm{u}\mathrm{p}\;\mathrm{C}\mathrm{o}\mathrm{n}\mathrm{v}}_{3\times 3} 表示 3\times 3 的分组卷积; {{X}}_{\mathrm{F}\mathrm{P}\mathrm{N}} 表示经过 FPN 生成的语义信息。
{P}_{{\mathrm{Conv}}}={c}_{1}\times k\times k\times {c}_{2}\;, {P}_{\mathrm{Grou{p}}\;{\mathrm{Conv}}}=\left(\frac{{c}_{1}}{g}\times k\times k\times \frac{{c}_{2}}{g}\right)\times g\;, 式中: {c}_{1} 表示输入通道数;k表示卷积核的大小; {c}_{2} 表示输出通道数;g表示分组数。
然后,考虑到分类和定位任务在关注目标上存在差异,分别聚焦于不同的层级以及感受野,并且前期的交互任务不可避免地为这两个不同任务引入了一定程度的特征冲突。所以,设计了任务分解模块DTG,通过通道注意力机制动态计算特定任务的特征,促进任务分解。具体而言,通过全局平均池化层获得通道维度的全局特征。接着,经过由两个卷积的全连接层构成的激励阶段,对通道注意力进行加权计算。之后,利用权重对特征图进行动态计算,生成分类任务和定位任务特定的特征。具体过程的表达式为
{{w}}=\delta \left({{{\mathrm{FC}}}}_{2}\left({{\mathrm{ReLu}}}\left({{{\mathrm{FC}}}}_{1}\left({{\mathrm{GAP}}}\left({{X}}_{{\mathrm{{inter}}}}\right)\right)\right)\right)\right)\;, {{X}}_{{\rm{{t}{a}{s}{k}}}\_{\rm{{c}{l}{s}}}}={\rm{Scale}}\cdot {\rm{Conv}}\left({w}\cdot {{X}}_{{\mathrm{{i}{n}{t}{e}{r}}}}\right)\;, {{X}}_{{\mathrm{{t}{a}{s}{k}}}\_{\mathrm{{r}{e}{g}}}}={\rm{Conv}}\left({w}\cdot {{X}}_{{\mathrm{{i}{n}{t}{e}{r}}}}\right)\;, 式中: \mathrm{\delta } 表示sigmoid函数;GAP(·)表示全局平均池层; {{\mathrm{F}}\mathrm{C}}_{1} 和 {{{\mathrm{F}}}{{\mathrm{C}}}}_{2} 表示通道注意力的激励阶段由两个 1\times 1 卷积的全连接层;Scale表示对不同尺度特征进行缩放; {{X}}_{\mathrm{t}\mathrm{a}\mathrm{s}\mathrm{k}\_\mathrm{c}\mathrm{l}\mathrm{s}} 表示生成的分类任务特定的特征; {{X}}_{\mathrm{t}\mathrm{a}\mathrm{s}\mathrm{k}\_\mathrm{r}\mathrm{e}\mathrm{g}} 表示生成的定位任务的特定特征。
2.3 模型剪枝
经过ETMFPN和LDTG-Head的轻量化设计后,模型在参数量和模型大小方面有所改善,但仍然存在参数冗余和模型过大的问题。为了在保证模型对小目标检测效果的同时,减少参数冗余和计算量,进一步采用基于幅度的层自适应稀疏度的剪枝算法(layer-adaptive sparsity for the magnitude-based pruning, LAMP)对改进后的模型进行剪枝,最大限度降低其对算力资源的消耗。
在深度学习网络中,网络连接的权重代表了输入信号的重要性。LAMP 方法的核心思想是根据每一层参数的重要性来自适应进行剪枝,修剪权重较小、对模型贡献不大的节点。与传统的统一全局剪枝不同,LAMP是根据各层实际情况进行针对性处理,有效解决了传统全局剪枝导致的层失效问题。
LAMP具体剪枝过程如下:
首先,为每层计算权重|W|并按照升序排列,根据式(12)计算LAMP分数( score )。
{{score}}\left({u},{W}\right)=\frac{{\left({W}\left[{u}\right]\right)}^{2}}{{{\displaystyle\sum }_{{p}\geqslant {u}}\left({W}\left[{p}\right]\right)}^{2}}\;, 式中:W(u)、W(p)分别表示索引u、p映射的权重项。由于按照u<p的顺序排列,此时W(u)<W(p)。LAMP分数保证了每一层至少有一个评分为1的最优通道,有效避免了层失效问题。
然后,预先设置一个修剪比例,LAMP将 score 小于或等于阈值的权重对应的掩码矩阵元素置为0,标记为需要剪枝的权重。接着更新权重,重复以上步骤,自动确定层级稀疏性,直到满足预先设定的稀疏性要求。这样的设计能有效平衡通道重要性,实现自适应的逐层级稀疏。最后,剪枝后的模型继续进行微调训练,从而恢复或提升模型性能。
3. 实验及结果分析
3.1 实验数据集
本次实验选用 VisDrone2019 数据集,该数据集内的图像采集于不同场景以及各类天气、光照条件下 。其中,涵盖了6471张训练图像、548张验证图像以及1610张测试图像,共有10类非均匀分布的对象。这些图像涵盖了各种角度、高度、光照条件和分辨率,其中物体尺寸较小,数量较大,可以有效验证网络模型用于小目标检测的性能。图7展示了该数据集的部分图像。
3.2 实验环境及评价指标
在本实验中,CPU为12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz,显卡为RTX 3080,显存为10 GB。输入图像统一调整大小为640 pixel×640 pixel。在训练设置方面,选用随机梯度下降法(stochastic gradient descent, SGD)优化器,动量设定为0.9,权重衰减值设为0.0005,初始学习率为0.01。训练时的批大小设定为4,对于非最大抑制(non-maximum suppression, NMS),其交并比(intersection over union, IoU)阈值被设置成0.7,迭代次数为300次。
为了评估本算法的有效性,采用在IoU阈值为0.5时,所有目标类别平均均值(mean average precision,mAP)精度和IoU阈值处于0.50至0.95(步长设定为0.05)的10个阈值下的检测精度的平均值 {{m}{A}{P}}_{0.5:0.95} 作为综合衡量模型性能的相关评价指标。采用模型参数量、计算量、模型大小等用来衡量模型的复杂程度,复杂程度越小代表模型更加轻量化,更适合边缘设备的部署。同时,采用平均精度(average precision, AP)来评估模型针对单个目标类别的检测性能。AP和mAP计算过程为
{{Precision}}=\frac{{T}{P}}{{T}{P}+{F}{P}} \;, {{ Recall}}=\frac{{T}{P}}{{T}{P}+{F}{N}} \;, {{AP}}={\int }_{0}^{1}{P}{r}{e}{c}{i}{s}{i}{o}{n}\left({R}{e}{c}{a}{l}{l}\right){{\mathrm{d}}}\left({R}{e}{c}{a}{l}{l}\right)\;, {{mAP}}=\frac{\displaystyle{\sum} _{{i}=1}^{{N}}{{A}{P}}_{{i}}}{{N}} \;, 式中:TP表示真阳性,即实际为正样本且被准确地标记为正样本的情况;FP 表示假阳性,即原本属于负样本,却被错误地标识成了正样本;FN表示正样本被错误地判定为负样本;N表示类别总数。
3.3 对比实验
为了检验所提模型的有效性,在VisDrone数据集中,将其与其他先进的检测算法进行对比。在表1中,呈现出了数据集内10类目标在不同算法下的AP、 {{m}{A}{P}}_{0.5} 结果,以及每种算法所的参数量。可以看出,对比其他算法,HETMNet在行人、人、汽车、面包车、卡车、三轮车、遮阳棚三轮车、巴士和摩托等尺寸较小和较大的目标上AP表现出了较好的检测性能。这表明HETMNet在各种场景下都有较好的检测性能,能在使用较少模型参数量,在不同类型目标的检测性能上超越其他算法,尤其是YOLOv9、YOLOv10、Mamba-YOLO等目前最新的算法。值得一提的是,HETMNet的参数量只有4.8 M,在 {{m}{A}{P}}_{0.5} 检测精度高于参数量达54.2 M的YOLOX。进一步验证HETMNet在处理无人机图像目标检测算法时具有更大的优势,也更适合边缘设备的部署。
Comparison results of AP and params of different algorithms on VisDrone dataset
不同算法在 VisDrone 数据集上的平均精度和参数量对比结果
Method AP/% {mAP}_{0.5} /% Params/M Pedestrian People Bicycle Car Van Truck Tricycle Awning-Tricycle Bus Motor Faster R-CNN[33] 20.9 14.8 7.3 51.0 29.7 19.5 14.0 8.8 30.5 21.2 21.8 — Cascade R-CNN 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 — YOLOv5 39.0 31.3 11.2 73.5 35.4 29.5 20.5 11.1 43.1 37.0 33.2 7.0 YOLOX[34] 34.8 24.5 16.9 72.4 34.4 40.5 23.1 17.8 53.1 36.0 35.3 54.2 YOLOv7[35] 37.9 34.6 9.4 76.1 36.3 29.8 20.1 10.6 43.2 41.8 34.0 6.0 YOLOv8 40.3 30.1 12.5 77.7 45.8 36.0 27.0 14.9 54.5 42.7 38.2 10.6 YOLOv9[36] 42.4 33.4 14.2 79.5 45.8 39.4 29.5 16.9 57.5 44.5 40.3 6.8 YOLOv10[37] 43.4 34.7 14.5 80.5 46.5 37.3 28.0 15.8 55.2 45.7 40.2 6.9 Mamba-YOLO[38] 41.0 31.7 11.5 79.3 44.2 33.2 26.1 13.8 56.0 43.0 38.0 5.7 BDAD-YOLO[39] 37.8 30.0 10.5 77.0 42.4 32.5 24.8 13.6 53.0 39.6 36.1 3.2 HETMNet(ours) 45.2 35.8 14.2 81.6 49.7 41.1 30.7 18.0 60.5 51.1 42.4 4.8 3.4 消融实验结果与分析
为验证多尺度特征高效传递金字塔网络(ETMFPN)、轻量化动态任务引导检测头(LDTG-Head)、LAMP剪枝对HETMNet的贡献,设计了5组消融实验,实验所得结果如表2所示。表2中模型1为原始YOLOv8模型,模型2表示使用ETMFPN替换模型1颈部的PAFPN网络,ETMFPN通过缩短传递路径实现了模型的轻量化,模型参数量降低0.9 M、模型大小也减少了1.9 MB。另外,在模型性能上也没有下降,通过HOAF模块捕捉高阶特征自适应融合各层特征,丰富了特征的非线性表达能力,使当前目标与上下文信息结合, {{m}{A}{P}}_{0.5:0.95} 指标提升2.3%。模型3表示在模型1的基础上将原始检测头替换成LDTG-Head,从实验结果可以看出,LDTG-Head在检测精度上大幅提升, {{m}{A}{P}}_{0.5} 提升了2.6%, {{m}{A}{P}}_{0.5:0.95} 上提升了2.0%,同时设计的轻量化共享检测头也使得模型在复杂度上变得更加轻量化,参数量减少了23.6%,模型大小减少了23.7%。模型4表示在模型1的基础上同时使用ETMFPN和LDTG-Head,从实验结果可以看出模型的参数量减少1.4 M,模型大小也减少2.7 MB。同时,检测精度也相比单独使用时有了相互促进的作用。模型5表示在模型4的改进模型上使用LAMP剪枝,在保持原始精度的同时 {{m}{A}{P}}_{0.5} 提升了0.4%, {{m}{A}{P}}_{0.5:0.95} 提升0.3%,参数量降低了47.8%,计算量降低了28.7%,模型大小减少了8.9 MB。通过减少冗余的通道,实现了模型的轻量化,同时也实现了较优的检测精度。
Results of HETMNet's ablation experiment on the VisDrone dataset
HETMNet在VisDrone数据集上的消融实验结果
Model ETMFPN LDTG-Head LAMP {{m}{A}{P}}_{0.5} /% {{m}{A}{P}}_{0.5:0.95} /% Params/M GFLOPs Size/MB Model 1 — — — 38.2 22.8 10.6 28.5 21.5 Model 2 √ — — 41.5 25.1 9.7 29.5 19.6 Model 3 — √ — 40.8 24.8 8.1 24.3 16.4 Model 4 √ √ — 42.0 25.7 9.2 28.6 18.8 Model 5 √ √ √ 42.4 26.0 4.8 20.4 9.9 为了验证所提ETMFPN具有更好的效果,在不同的金字塔网络上进行了消融实验,如表3所示。可以看出ETMFPN相较于双路径金字塔网络PAFPN更适合小目标检测且更加轻量化,与先进的解决跨层特征丢失问题的金字塔网络GoldYOLO和BiFPN相比,其 {{m}{A}{P}}_{0.5} 与 {{m}{A}{P}}_{0.5:0.95} 更具有优势。证明了HOAF通过获取高阶特征并在不同层之间直接传递的设计,具有更好的效果。
ETMFPN ablation experiment results
ETMFPN消融实验结果
Model {{m}{A}{P}}_{0.5} /% {{m}{A}{P}}_{0.5:0.95} /% Params/M +PAFPN 38.2 22.8 10.6 +GoldYOLO 40.5 24.4 13.0 +BiFPN 40.9 24.9 7.0 +ETMFPN 41.5 25.1 9.7 为了实现模型检测精度与参数量之间的平衡,选择了不同的LAMP剪枝比例进行实验,如表4所示。剪枝比例等于剪枝前模型计算量与剪枝后模型计算量之比。剪枝比例越大,模型的参数量越小,为了在保持原有检测精度的同时实现了模型的轻量化,选择的剪枝比例为1.40,检测精度比未剪枝的模型 {{m}{A}{P}}_{0.5} 增长0.4%,参数量降低47.8%。
LAMP ablation experiment results
LAMP消融实验结果
Speed_up {{m}{A}{P}}_{0.5} /% Params/M — 42.0 9.2 1.25 42.6 5.6 1.35 42.4 5.0 1.40 42.4 4.8 1.45 42.3 4.6 3.5 可视化分析
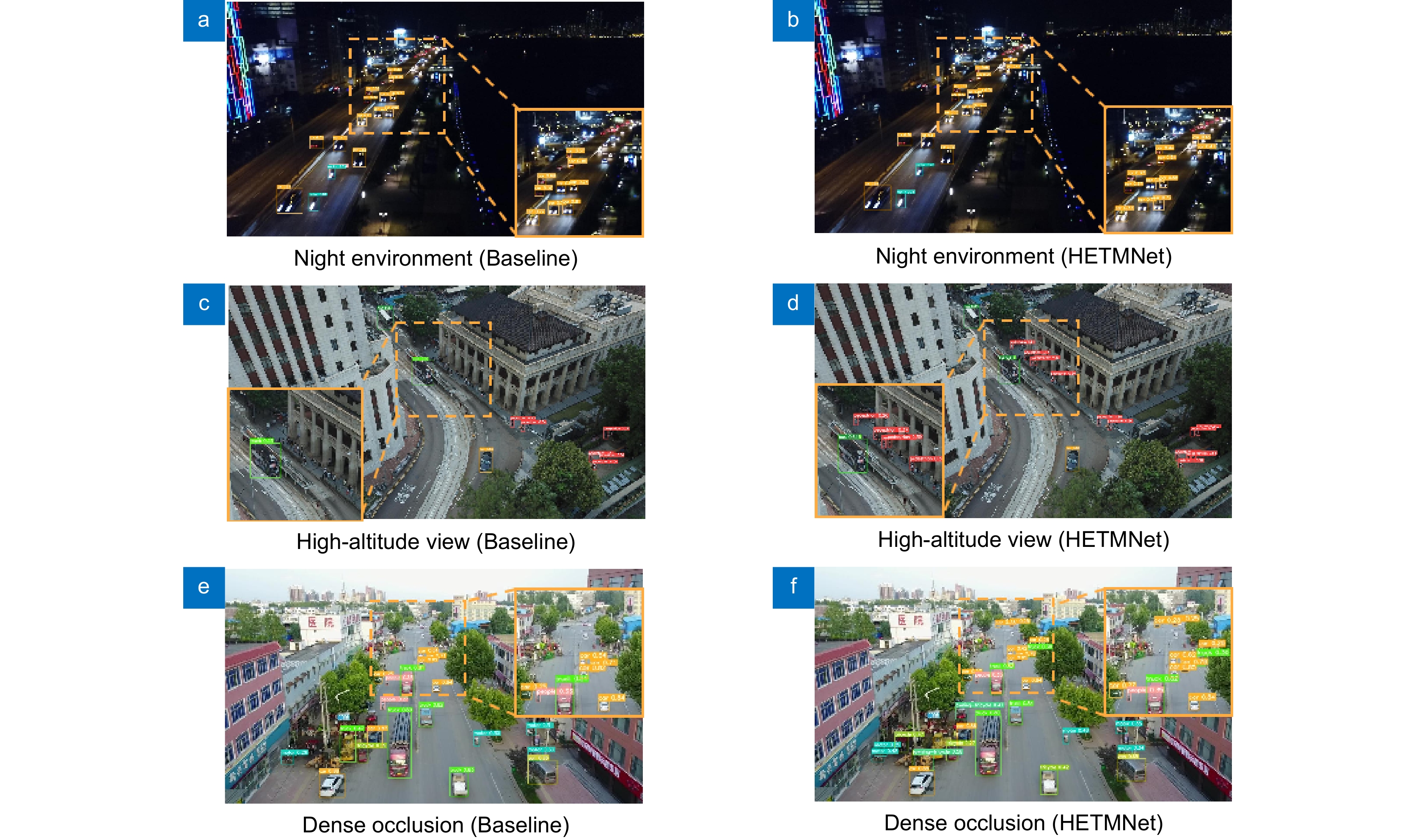
为了充分验证HETMNet在不同场景里的适用性,从VisDrone数据集中选取了部分涵盖夜间环境、高空视野以及密集遮挡等复杂状况的图像进行测试,检测结果如图8所示。对比图8(a, b)可知,在光线昏暗并且小目标存在密集遮挡的场景下,与基准算法相比,HETMNet对小目标展现出更高的检测准确率。对比图8(c, d)可知,在高空条件下,HETMNet的总体检测精度优于基准算法,能够更加聚焦目标的中心位置,有效抑制背景噪声,同时保留对目标判定更为关键的特征信息,在复杂背景中展现出更为出色的检测性能。对比图8(e, f)可知,HETMNet在密集遮挡状况下,可以精准检测出远视距位置的汽车小目标。整体来讲,HETMNet模型在复杂场景,尤其是远视距环境中的检测性能得到了显著提升。
![图 8 VisDrone 数据集上的复杂场景目标检测效果对比。(a)(b)夜间环境;(c)(d)高空视角;(e)(f)密集遮挡]() 图 8
图 8VisDrone 数据集上的复杂场景目标检测效果对比。(a)(b)夜间环境;(c)(d)高空视角;(e)(f)密集遮挡
Figure 8.Comparison of target detection effectiveness in complex scenes on VisDrone dataset. (a)(b) Night environment; (c)(d) High-altitude view; (e)(f) dense occlusion scenes
4. 结 论
针对无人机航拍图像检测存在的小目标检测精度低和模型参数量大的问题,提出基于超图计算的多尺度特征高效传递小目标检测算法HETMNet。在颈部设计ETMFPN替换原始的PAFPN,缩短特征传递路径,减少信息损失。利用超图构建高阶特征丰富模型的上下文特征。在目标预测方面,设计LDTG-Head,利用共享机制大大减少了参数量实现了轻量化,同时使用动态任务引导对齐分类和定位任务,再逐一分解,提高任务之间的相关性。引入LAMP剪枝,自适应选择对模型贡献小的冗余通道进行修建,使模型能够在保持原始性能的基础上进一步减少复杂度。在VisDrone数据集上进行实验,实验结果显示,在模型参数量仅为4.8 M时, {{m}{A}{P}}_{0.5} 达到了42.4%。相较于基准算法,该模型参数量降低54.7%,而精度提升了4.2%。验证了HETMNet模型的有效性,能较好地应对无人机图像目标检测任务。下一步将继续研究高效目标检测算法,保证精准度和轻量化的同时,进一步提升检测的实时性。
利益冲突
所有作者声明无利益冲突
-
参考文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587. https://doi.org/10.1109/CVPR.2014.81.
[2] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322.
[3] Cai Z W, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6154–6162. https://doi.org/10.1109/CVPR.2018.00644.
[4] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. https://doi.org/10.1109/CVPR.2016.91.
展开 -
版权信息
版权属于中国科学院光电技术研究所,但文章内容可以在本网站免费下载,以及免费用于学习和科研工作 -
关于本文
引用本文
Citation:孙叶美, 桑学婷, 张艳, 刘国瑞, 陈帅宇. 基于超图计算的高效传递多尺度特征小目标检测算法[J]. 光电工程, 2025, 52(5): 250061. DOI: 10.12086/oee.2025.250061Citation:Sun Yemei, Sang Xueting, Zhang Yan, Liu Guorui, Chen Shuaiyu. Hypergraph computed efficient transmission multi-scale feature small target detection algorithm. Opto-Electronic Engineering 52, 250061 (2025). DOI: 10.12086/oee.2025.250061导出引用出版历程
- 收稿日期 2025-02-27
- 修回日期 2025-04-07
- 录用日期 2025-04-07
- 刊出日期 2025-05-29
文章计量
访问数(1003) PDF下载数(32)
- 1003 访问数
- 32 下载数
 下载:
下载: