
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Li H Y, Chen Y Y, Jiang Z D, et al. Unsupervised light field depth estimation based on sub-light field occlusion fusion[J]. Opto-Electron Eng, 2024, 51(10): 240166. doi: 10.12086/oee.2024.240166

|
Unsupervised light field depth estimation based on sub-light field occlusion fusion
-
Abstract
Light field depth estimation is an important scientific problem of light field processing and applications. However, the existing studies ignore the geometric occlusion relationship among views in the light field. By analyzing the occlusion among different views, an unsupervised light field depth estimation method based on sub-light field occlusion fusion is proposed. The proposed method first adopts an effective sub-light field division mechanism to consider the depth relationship at different angular positions. Specifically, the views on the primary and secondary diagonals of the light field sub-aperture arrays are divided into four sub-light fields, i.e., top-left, top-right, bottom-left, and bottom-right. Then, a spatial pyramid pooling feature extraction and a U-Net network are leveraged to estimate the depths of the sub-light fields. Finally, an occlusion fusion strategy is designed to fuse all sub-light field depths to obtain the final depth. This strategy assigns greater weights to the sub-light field depth with higher accuracy in the occlusion region, thus reducing the occlusion effect. In addition, a weighted spatial and an angular consistency loss are employed to constrain network training and enhance robustness. Experimental results demonstrate that the proposed method exhibits favorable performance in both quantitative metrics and qualitative comparisons.-
Keywords:
- light field /
- depth estimation /
- unsupervised /
- sub-light field division /
- occlusion fusion
-
-
References
[1] Rabia S, Allain G, Tremblay R, et al. Orthoscopic elemental image synthesis for 3D light field display using lens design software and real-world captured neural radiance field[J]. Opt Express, 2024, 32(5): 7800−7815. doi: 10.1364/OE.510579 [2] Charatan D, Li S L, Tagliasacchi A, et al. pixelSplat: 3D gaussian splats from image pairs for scalable generalizable 3d reconstruction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, 2024: 19457–19467. [3] 李玉龙, 陈晔曜, 崔跃利, 等. LF-UMTI: 基于多尺度空角交互的无监督多曝光光场图像融合[J]. 光电工程, 2024, 51(6): 240093. doi: 10.12086/oee.2024.240093 Li Y L, Chen Y Y, Cui Y L, et al. LF-UMTI: unsupervised multi-exposure light field image fusion based on multi-scale spatial-angular interaction[J]. Opto-Electron Eng, 2024, 51(6): 240093. doi: 10.12086/oee.2024.240093 [4] 吕天琪, 武迎春, 赵贤凌. 角度差异强化的光场图像超分网络[J]. 光电工程, 2023, 50(2): 220185. doi: 10.12086/oee.2023.220185 Lv T Q, Wu Y C, Zhao X L. Light field image super-resolution network based on angular difference enhancement[J]. Opto-Electron Eng, 2023, 50(2): 220185. doi: 10.12086/oee.2023.220185 [5] Jeon H G, Park J, Choe G, et al. Accurate depth map estimation from a lenslet light field camera[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, 2015: 1547–1555. https://doi.org/10.1109/CVPR.2015.7298762. [6] Wang T C, Efros A A, Ramamoorthi R. Occlusion-aware depth estimation using light-field cameras[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, 2015: 3487–3495. https://doi.org/10.1109/ICCV.2015.398. [7] Zhang S, Sheng H, Li C, et al. Robust depth estimation for light field via spinning parallelogram operator[J]. Comput Vis Image Underst, 2016, 145: 148−159. doi: 10.1016/j.cviu.2015.12.007 [8] Han K, Xiang W, Wang E, et al. A novel occlusion-aware vote cost for light field depth estimation[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 44(11): 8022−8035. doi: 10.1109/TPAMI.2021.3105523 [9] Tsai Y J, Liu Y L, Ouhyoung M, et al. Attention-based view selection networks for light-field disparity estimation[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, 2020: 12095–12103. https://doi.org/10.1609/aaai.v34i07.6888. [10] Wang Y Q, Wang L G, Liang Z Y, et al. Occlusion-aware cost constructor for light field depth estimation[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, 2022: 19777–19786. https://doi.org/10.1109/CVPR52688.2022.01919. [11] Chao W T, Wang X C, Wang Y Q, et al. Learning sub-pixel disparity distribution for light field depth estimation[J]. IEEE Trans Comput Imaging, 2023, 9: 1126−1138. doi: 10.1109/TCI.2023.3336184 [12] Srinivasan P P, Wang T Z, Sreelal A, et al. Learning to synthesize a 4D RGBD light field from a single image[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, 2017: 2262–2270. https://doi.org/10.1109/ICCV.2017.246. [13] Peng J Y, Xiong Z W, Wang Y C, et al. Zero-shot depth estimation from light field using a convolutional neural network[J]. IEEE Trans Comput Imaging, 2020, 6: 682−696. doi: 10.1109/TCI.2020.2967148 [14] Zhou W H, Zhou E C, Liu G M, et al. Unsupervised monocular depth estimation from light field image[J]. IEEE Trans Image Process, 2020, 29: 1606−1617. doi: 10.1109/TIP.2019.2944343 [15] Jin J, Hou J H. Occlusion-aware unsupervised learning of depth from 4-D light fields[J]. IEEE Trans Image Process, 2022, 31: 2216−2228. doi: 10.1109/TIP.2022.3154288 [16] Zhang S S, Meng N, Lam E Y. Unsupervised light field depth estimation via multi-view feature matching with occlusion prediction[J]. IEEE Trans Circuits Syst Video Technol, 2024, 34(4): 2261−2273. doi: 10.1109/TCSVT.2023.3305978 [17] Godard C, Aodha O M, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 6602–6611. https://doi.org/10.1109/CVPR.2017.699. [18] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90. [19] Honauer K, Johannsen O, Kondermann D, et al. A dataset and evaluation methodology for depth estimation on 4D light fields[C]//Proceedings of the 13th Asian Conference on Computer Vision, Taipei, China, 2016: 19–34. https://doi.org/10.1007/978-3-319-54187-7_2. [20] Shi J L, Jiang X R, Guillemot C. A framework for learning depth from a flexible subset of dense and sparse light field views[J]. IEEE Trans Image Process, 2019, 28(12): 5867−5880. doi: 10.1109/TIP.2019.2923323 [21] Blender website[EB/OL]. [2024-09-01]. https://www.blender.org/. [22] Rerabek M, Ebrahimi T. New light field image dataset[C]//Proceedings of the 8th International Conference on Quality of Multimedia Experience, Lisbon, 2016: 1–2. [23] Raj A S, Lowney M, Shah R, et al. Stanford lytro light field archive[EB/OL]. [2024-07]. http://lightfields.stanford.edu/LF2016.html. -
Overview
Light is an important medium for humans to observe and perceive the real world, while traditional imaging approaches only record limited light information. Light field imaging can simultaneously acquire the intensity and direction information of light rays, thereby enabling a more accurate perception of complex dynamic environments. Currently, it has been applied to many visual tasks such as 3D scene reconstruction, digital refocusing, view synthesis, and occlusion removal. It is regarded as one of the main technologies for immersive media. Light field depth estimation is an important scientific problem of light field processing and applications. In recent years, deep learning has shown strong nonlinear fitting capabilities and achieved favorable results in light field depth estimation, but the generalization capability of supervised methods in real-world scenes is limited. Besides, the existing studies ignore the geometric occlusion relationship among views in the light field. By analyzing the occlusion issue among different views, an unsupervised light field depth estimation method based on sub-light field occlusion fusion is proposed. Firstly, an effective sub-light field division mechanism is employed to consider the depth relationship at different angular positions. Specifically, the view on the primary and secondary diagonals of the light field sub-aperture array are divided into four sub-light fields, i.e., top-left, top-right, bottom-left, and bottom-right. Secondly, a spatial pyramid pooling is leveraged for feature extraction to capture multi-scale context information, along with a U-Net network to estimate the depths of the sub-light fields. Finally, an occlusion fusion strategy is designed to fuse all sub-light field depths to obtain the final depth, which assigns greater weights to the sub-light field depth map with higher accuracy in the occlusion region, so as to reduce the occlusion effect. In addition, a weighted spatial and an angular consistency loss are used to constrain network training and enhance robustness. Extensive experimental results on the benchmark datasets show that the proposed method outperforms the existing methods in both quantitative and qualitative comparison. In particular, the proposed method exhibits favorable performance on real-world datasets established with light field cameras. Moreover, detailed ablation studies validate the effectiveness of sub-light field division, occlusion fusion, and loss functions involved in the proposed method.
-
Access History

Figures(10)
Tables(4)
Article Metrics

Export File
Citation
Li H Y, Chen Y Y, Jiang Z D, et al. Unsupervised light field depth estimation based on sub-light field occlusion fusion[J]. Opto-Electron Eng, 2024, 51(10): 240166. doi: 10.12086/oee.2024.240166
Format
Content
 DownLoad:
DownLoad:

-
Figure 1.
Illustrations of center view and warping errors of left, right, top, and bottom views. (a) Center view; (b) Warping error of left view; (c) Warping error of right view; (d) Warping error of top view; (e) Warping error of bottom view
-
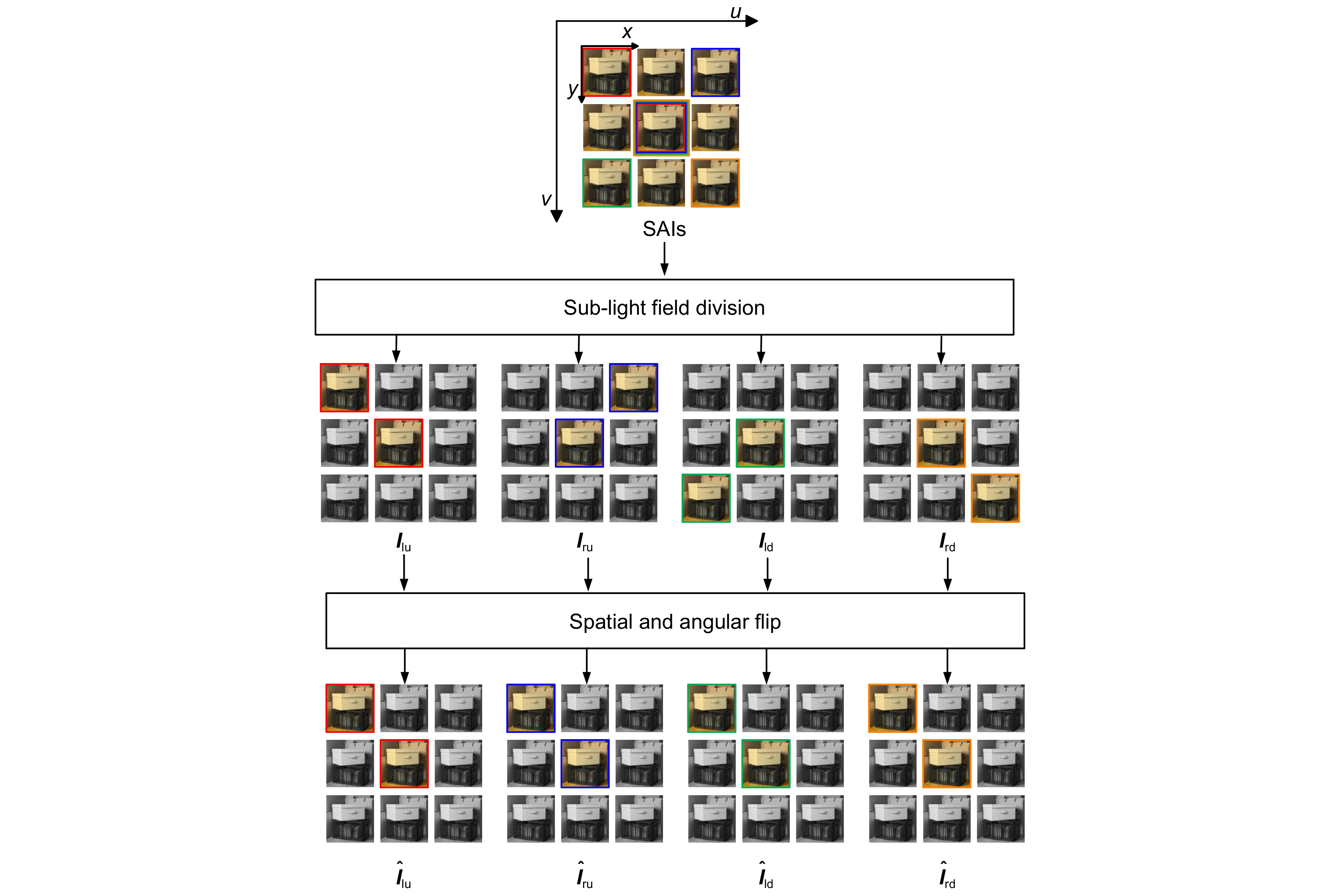
Figure 2.
Sub-light field division and spatial and angular flip ( 3×3 as an example)
-
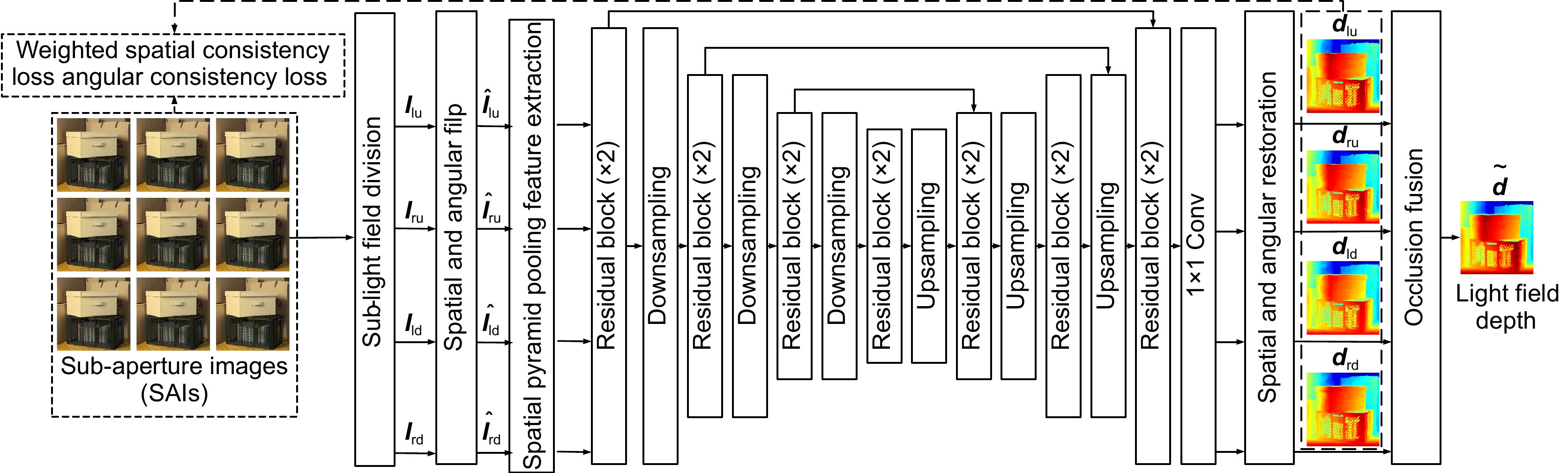
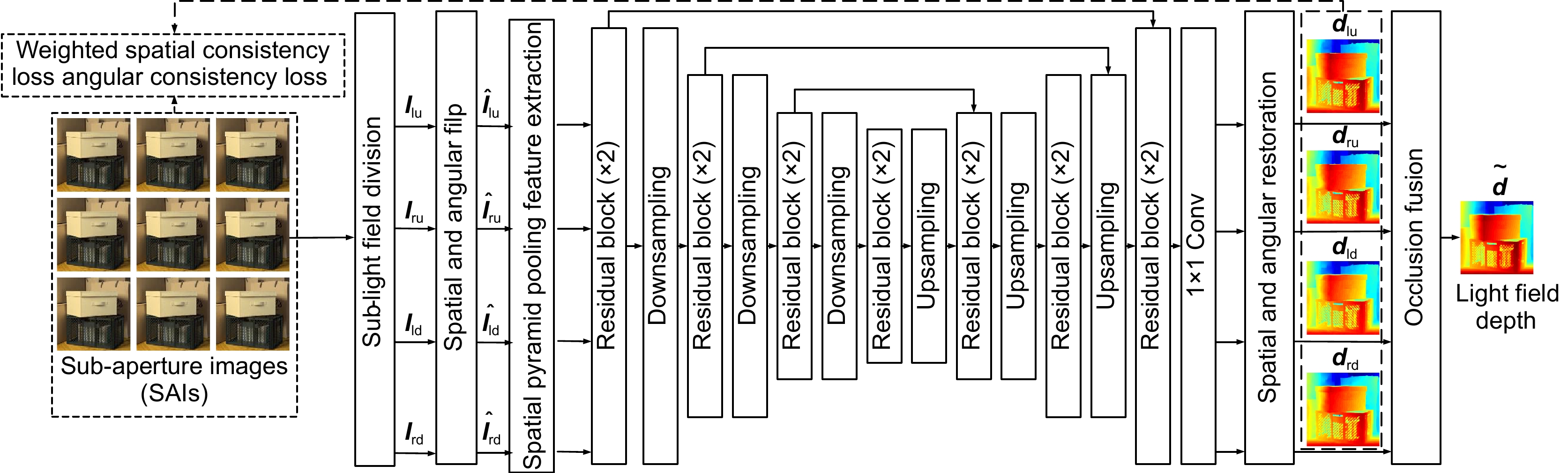
Figure 3.
Overall network framework of the proposed method
-
Figure 4.
Spatial pyramid polling feature extraction model
-
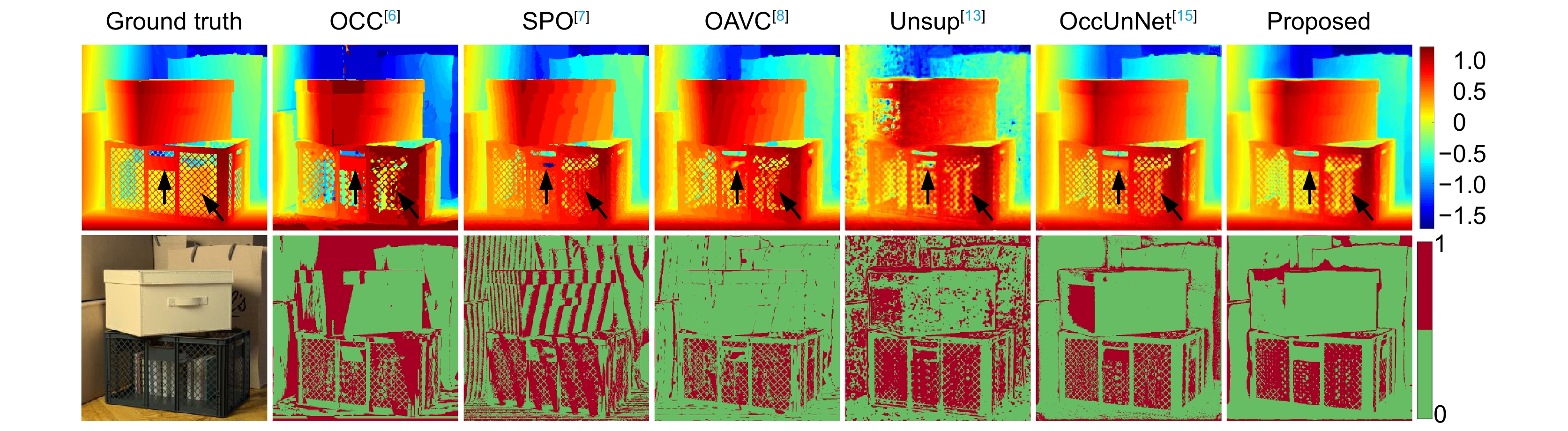
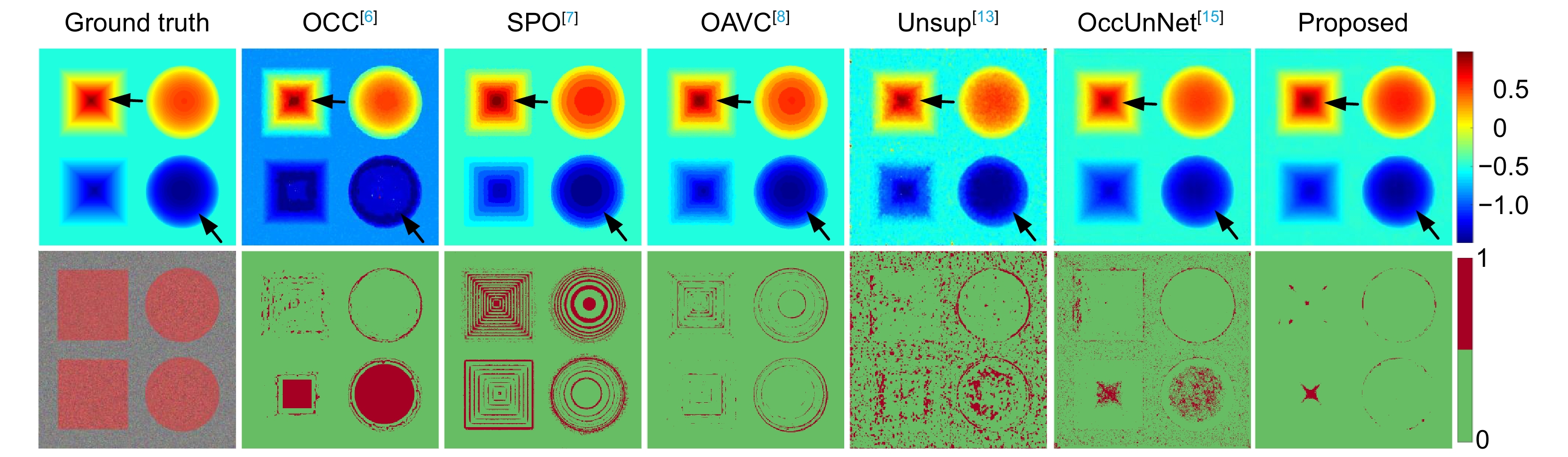
Figure 5.
Comparison of depths and bad pixel maps estimated by different methods on Boxes from the HCI new dataset [19]
-
Figure 6.
Comparison of depths and bad pixel maps estimated by different methods on Pyramids from the HCI new dataset [19]
-
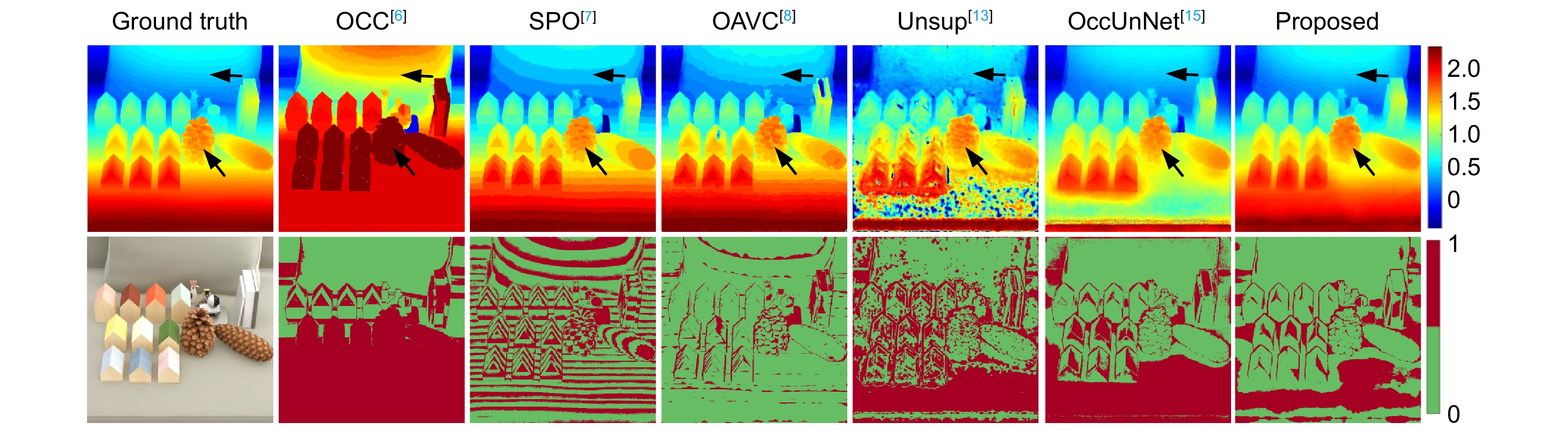
Figure 7.
Comparison of depths and bad pixel maps estimated by different methods on Pinenuts from the DLF dataset [20]
-
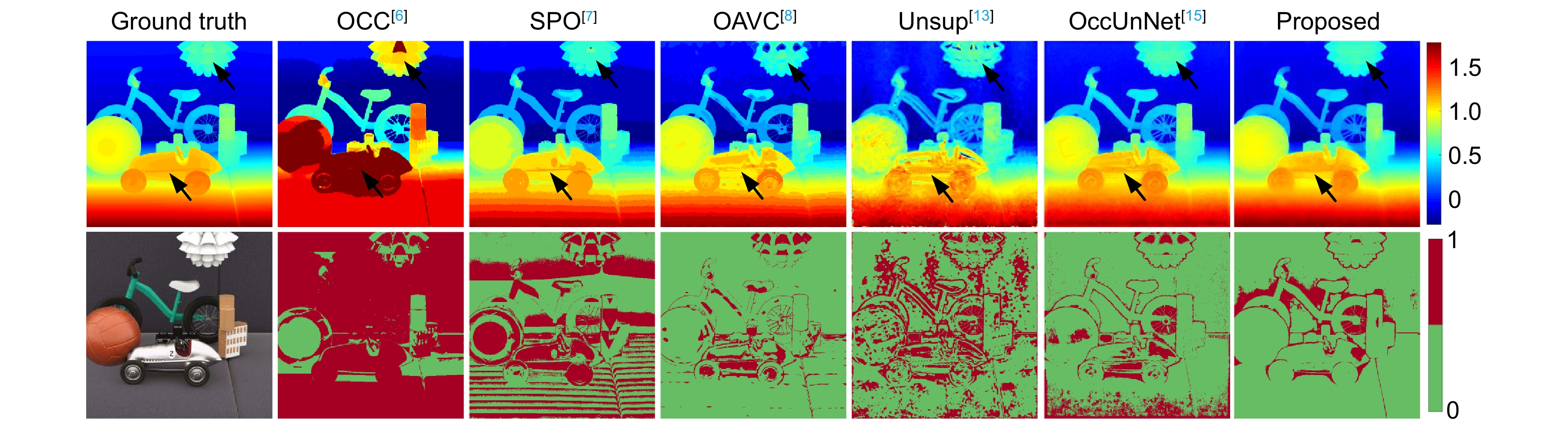
Figure 8.
Comparison of depths and bad pixel maps estimated by different methods on Toys from the DLF dataset [20]
-
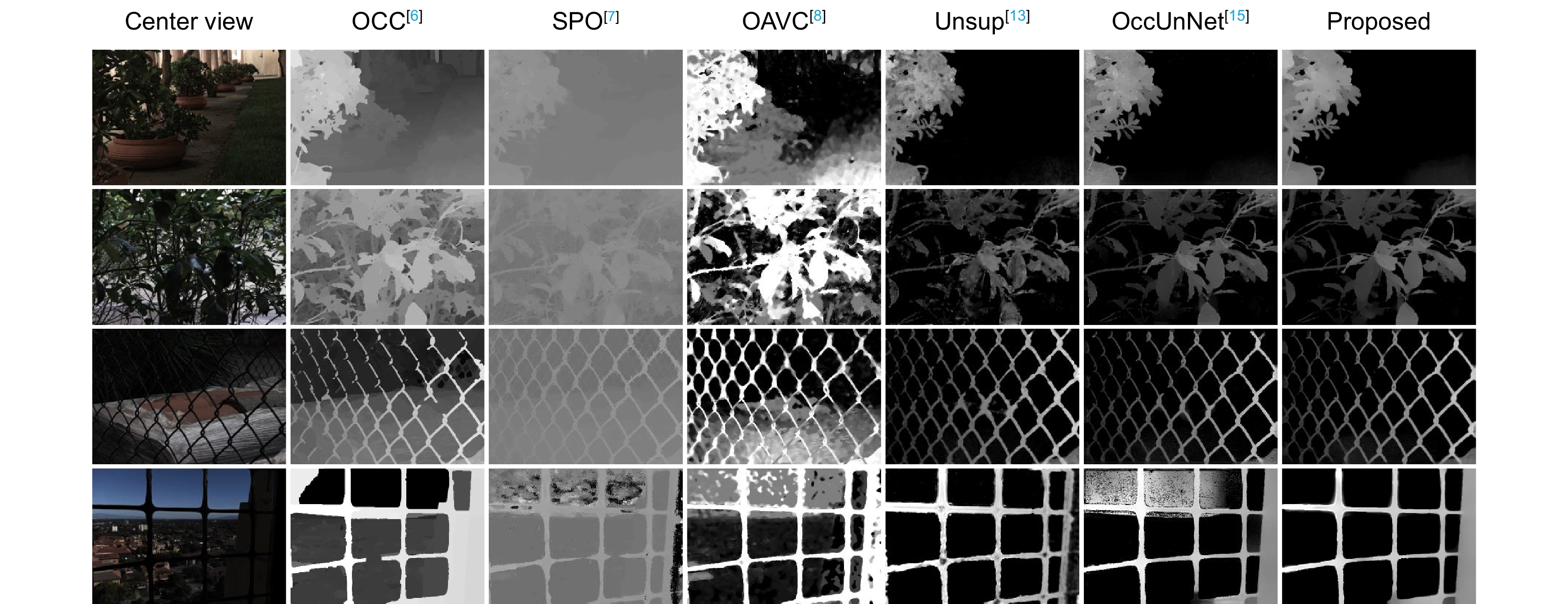
Figure 9.
Comparison of depths estimated by different methods on real-world data from the Stanford Lytro dataset [23]
- Figure .


