
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |

|
The joint discriminative and generative learning for person re-identification of deep dual attention
-
Abstract
In the task of person re-identification, there are problems such as difficulty in labeling datasets, small sample size, and detail feature missing after feature extraction. The joint discriminative and generative learning for person re-identification of the deep dual attention is proposed against the above issues. Firstly, the author constructs a joint learning framework and embeds the discriminative module into the generative module to realize the end-to-end training of image generative and discriminative. Then, the generated pictures are sent to the discriminative module to optimize the generative module and the discriminative module simultaneously. Secondly, according to the connection between the channels of the attention modules and the connection between the attention modules in spaces, it merges all the channel features and spatial features and constructs a deep dual attention module. By embedding the models in the teacher model, the model can better extract the fine-grained features of the objects and improve the recognition ability. The experimental results show that the algorithm has better robustness and discriminative capability on the Market-1501 and the DukeMTMC-ReID datasets.-
Keywords:
- person re-identification /
- image generative /
- joint learning /
- attention /
- deep learning
-
-
References
[1] 宋婉茹, 赵晴晴, 陈昌红, 等. 行人重识别研究综述[J]. 智能系统学报, 2017, 12(6): 770-780. Song W R, Zhao Q Q, Chen C H, et al. Survey on pedestrian re-identification research[J]. CAAI Trans Intell Syst, 2017, 12(6): 770-780. [2] 冯霞, 杜佳浩, 段仪浓, 等. 基于深度学习的行人重识别研究综述[J]. 计算机应用研究, 2020, 37(11): 3220-3226, 3240. Feng X, Du J H, Duan Y N, et al. Research on person re-identification based on deep learning[J]. Appl Res Comput, 2020, 37(11): 3220-3226, 3240. [3] Matsukawa T, Okabe T, Suzuki E, et al. Hierarchical Gaussian descriptor for person re-identification[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 2016: 1363-1372. [4] Lisanti G, Masi I, Bagdanov A D, et al. Person re-identification by iterative re-weighted sparse ranking[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 37(8): 1629-1642. doi: 10.1109/TPAMI.2014.2369055 [5] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3754-3762. [6] Wei L H, Zhang S L, Gao W, et al. Person transfer GAN to bridge domain gap for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 79-88. [7] Ge Y X, Li Z W, Zhao H Y, et al. FD-GAN: pose-guided feature distilling GAN for robust person re-identification[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 1222-1233. [8] Deng W J, Zheng L, Ye Q X, et al. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 994-1003. [9] Song C F, Huang Y, Ouyang W L, et al. Mask-guided contrastive attention model for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 1179-1188. [10] Xu J, Zhao R, Zhu F, et al. Attention-aware compositional network for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 2119-2128. [11] Li W, Zhu X T, Gong S G. Harmonious attention network for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 2285-2294. [12] Zheng Z D, Yang X D, Yu Z D, et al. Joint discriminative and generative learning for person re-identification[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 2019: 2138-2147. [13] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 3-19. [14] Ma X, Guo J D, Tang S H, et al. DCANet: learning connected attentions for convolutional neural networks[Z]. arXiv: 2007.05099, 2020. [15] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 2016: 770-778. [16] 郭玥秀, 杨伟, 刘琦, 等. 残差网络研究综述[J]. 计算机应用研究, 2020, 37(5): 1292-1297. Guo Y X, Yang W, Liu Q, et al. Survey of residual network[J]. Appl Res Comput, 2020, 37(5): 1292-1297. [17] Zhong W L, Jiang L F, Zhang T, et al. A part-based attention network for person re-identification[J]. Multimed Tools Appl, 2020, 79(31): 22525-22549. doi: 10.1007/s11042-019-08395-2 [18] Wei L H, Zhang S L, Yao H T, et al. GLAD: global-local-alignment descriptor for scalable person re-identification[J]. IEEE Trans Multimed, 2019, 21(4): 986-999. doi: 10.1109/TMM.2018.2870522 [19] Miao J X, Wu Y, Liu P, et al. Pose-guided feature alignment for occluded person re-identification[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 542-551. [20] Zhuang Z J, Wei L H, Xie L X, et al. Rethinking the distribution gap of person re-identification with camera-based batch normalization[C]//Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 2020: 140-157. [21] Bai X, Yang M K, Huang T T, et al. Deep-person: learning discriminative deep features for person Re-identification[J]. Pattern Recognit, 2020, 98: 107036. doi: 10.1016/j.patcog.2019.107036 [22] Sun Y F, Xu Q, Li Y L, et al. Perceive where to focus: learning visibility-aware part-level features for partial person re-identification[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 2019: 393-402. [23] Qian X L, Fu Y W, Xiang T, et al. Pose-normalized image generation for person re-identification[C]//Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 650-667. -
Overview

Overview: Person re-identification is a technology that uses computer technology to determine whether there is a specific object in an image or video sequence. In the task of person re-identification, there are problems such as difficulty in labeling datasets, small sample size, and detail feature missing after feature extraction.The joint discriminative and generative learning for person re-identification of deep dual attention is proposed against the above issues. Firstly, the author constructs a joint learning framework and embeds the discriminative module into the generative module to realize the end-to-end training of images generative and discriminative. Then the generated pictures are sent to the discriminative module to optimize the generative module and discriminative module simultaneously. Secondly, we construct a deep dual attention module. Through the connection between the channels of the attention modules and the connection between attention modules in spaces, the information collected by the previous attention module is passed to the next attention module. The attention feature is fused with the currently extracted attention feature to ensure that the information between attention modules of the same dimension can flow in a feed-forward manner, effectively avoiding the frequent changes of the information between attention modules. At last, the author merges all channel features and spatial features. Due to the high similarity of the appearance of the images in the dataset, the teacher model recognition becomes more difficult. Therefore, the deep dual attention module is embedded in the teacher model to improve the recognition ability of the teacher model. The teacher model is used to assist the student model to learn the main features. The generated images are used as training samples to force students to learn fine-grained features independent of appearance features. The author merges the main features and fine-grained features to re-identification person. The experimental results show that Rank-1 and mAP used in this paper are superior to the advanced correlation algorithms.
-
Access History

Export File
Citation
Format
Content
 DownLoad:
DownLoad:

-
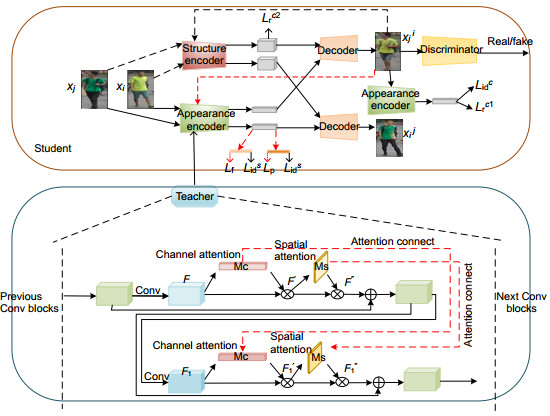
Figure 1.
Framework for teacher- student network
-
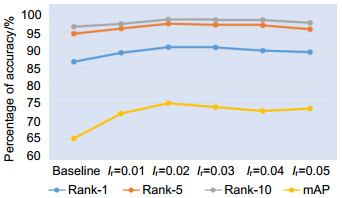
Figure 2.
Learning rate
-
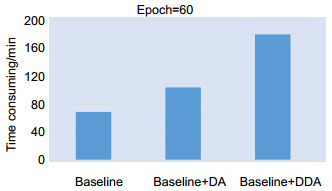
Figure 3.
Time-consuming comparison of different methods
-
Figure 4.
Visual contrast results of different stages of attention mechanism.


