
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Huang L, Lv T Q, Wu Y C, et al. Two-way guided updating network for light field image super-resolution[J]. Opto-Electron Eng, 2024, 51(12): 240222. doi: 10.12086/oee.2024.240222

|
Two-way guided updating network for light field image super-resolution
-
Abstract
Based on the four-dimensional representation of the two-plane model, the light field camera captures spatial and angular information of the three-dimensional scene simultaneously at the expense of image spatial resolution. To improve the spatial resolution of light field images, a two-way guided updating network for light field image super-resolution is built in this work. In the front of the network, different forms of image arrays are used as inputs, and the residual series and parallel convolution are constructed to realize the decoupling of spatial and angular information. Aiming at the decoupled spatial information and angular information, a two-way guide updating module is designed, which adopts step-by-step enhancement, fusion, and re-enhancement methods to complete the interactive guidance iterative update of spatial and angular information. Finally, the step-by-step updated angular information is sent to the simplified residual feature distillation module to realize data reconstruction. Many experimental results have confirmed that our proposed method achieves state-of-the-art performance while effectively controlling complexity. -
-
References
[1] Van Duong V, Huu T N, Yim J, et al. Light field image super-resolution network via joint spatial-angular and epipolar information[J]. IEEE Trans Comput Imaging, 2023, 9: 350−366. doi: 10.1109/TCI.2023.3261501 [2] Wang C C, Zang Y S, Zhou D M, et al. Robust multi-focus image fusion using focus property detection and deep image matting[J]. Expert Syst Appl, 2024, 237: 121389. doi: 10.1016/j.eswa.2023.121389 [3] Sakem A, Ibrahem H, Kang H S. Learning epipolar-spatial relationship for light field image super-resolution[C]// Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Vancouver, 2023: 1336–1345. https://doi.org/10.1109/CVPRW59228.2023.00140. [4] Cui Z L, Sheng H, Yang D, et al. Light field depth estimation for non-Lambertian objects via adaptive cross operator[J]. IEEE Trans Circuits Syst Video Technol, 2024, 34 (2): 1199−1211. doi: 10.1109/TCSVT.2023.3292884 [5] Chao W T, Wang X C, Wang Y Q, et al. Learning sub-pixel disparity distribution for light field depth estimation[J]. IEEE Trans Comput Imaging, 2023, 9: 1126−1138. doi: 10.1109/TCI.2023.3336184 [6] Wang Y Q, Wang L G, Wu G C, et al. Disentangling light fields for super-resolution and disparity estimation[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45 (1): 425−443. doi: 10.1109/TPAMI.2022.3152488 [7] Ding Y Q, Chen Z, Ji Y, et al. Light field-based underwater 3D reconstruction via angular re-sampling[J]. IEEE Trans Comput Imaging, 2023, 9: 881−893. doi: 10.1109/TCI.2023.3319983 [8] 张志俊, 吴庆阳, 邓亦锋, 等. 基于霍夫变换的结构光场3维成像方法[J]. 激光技术, 2023, 47 (4): 492−499. doi: 10.7510/jgjs.issn.1001-3806.2023.04.008 Zhang Z J, Wu Q Y, Deng Y F, et al. Structured light field 3-D imaging method based on Hough transform[J]. Laser Technol, 2023, 47 (4): 492−499. doi: 10.7510/jgjs.issn.1001-3806.2023.04.008 [9] Gao W, Fan S L, Li G, et al. A thorough benchmark and a new model for light field saliency detection[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45 (7): 8003−8019. doi: 10.1109/TPAMI.2023.3235415 [10] Chen G, Fu H Z, Zhou T, et al. Fusion-embedding Siamese network for light field salient object detection[J]. IEEE Trans Multimedia, 2024, 26: 984−994. doi: 10.1109/TMM.2023.3274933 [11] Chen Y L, Li G Y, An P, et al. Light field salient object detection with sparse views via complementary and discriminative interaction network[J]. IEEE Trans Circuits Syst Video Technol, 2024, 34 (2): 1070−1085. doi: 10.1109/TCSVT.2023.3290600 [12] Yeung H W F, Hou J H, Chen X M, et al. Light field spatial super-resolution using deep efficient spatial-angular separable convolution[J]. IEEE Trans Image Process, 2019, 28 (5): 2319−2330. doi: 10.1109/TIP.2018.2885236 [13] Wang Y Q, Yang J G, Wang L G, et al. Light field image super-resolution using deformable convolution[J]. IEEE Trans Image Process, 2021, 30: 1057−1071. doi: 10.1109/TIP.2020.3042059 [14] Yoon Y, Jeon H G, Yoo D, et al. Learning a deep convolutional network for light-field image super-resolution[C]//Proceedings of 2015 IEEE International Conference on Computer Vision Workshop, Santiago, 2015: 24–32. https://doi.org/10.1109/ICCVW.2015.17. [15] Zhang S, Lin Y F, Sheng H. Residual networks for light field image super-resolution[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 11046–11055. https://doi.org/10.1109/CVPR.2019.01130. [16] Jin J, Hou J H, Chen J, et al. Light field spatial super-resolution via deep combinatorial geometry embedding and structural consistency regularization[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 2260–2269. https://doi.org/10.1109/CVPR42600.2020.00233. [17] 吕天琪, 武迎春, 赵贤凌. 角度差异强化的光场图像超分网络[J]. 光电工程, 2023, 50 (2): 220185. doi: 10.12086/oee.2023.220185 Lv T Q, Wu Y C, Zhao X L. Light field image super-resolution network based on angular difference enhancement[J]. Opto-Electron Eng, 2023, 50 (2): 220185. doi: 10.12086/oee.2023.220185 [18] Chan K H, Im S K. Light-field image super-resolution with depth feature by multiple-decouple and fusion module[J]. Electron Lett, 2024, 60 (1): e13019. doi: 10.1049/ell2.13019 [19] Liang Z Y, Wang Y Q, Wang L G, et al. Angular‐flexible network for light field image super‐resolution[J]. Electron Lett, 2021, 57 (24): 921−924. doi: 10.1049/ell2.12312 [20] Wang S Z, Zhou T F, Lu Y, et al. Detail-preserving transformer for light field image super-resolution[C]//Proceedings of the 36th AAAI Conference on Artificial Intelligence, Vancouver, 2022: 2522–2530. https://doi.org/10.1609/aaai.v36i3.20153. [21] Wang Y Q, Wang L G, Yang J G, et al. Spatial-angular interaction for light field image super-resolution[C]// Proceedings of the 16th European Conference on Computer Vision, Glasgow, 2020: 290–308. https://doi.org/10.1007/978-3-030-58592-1_18. [22] Liu G S, Yue H J, Wu J M, et al. Intra-inter view interaction network for light field image super-resolution[J]. IEEE Trans Multimedia, 2023, 25: 256−266. doi: 10.1109/TMM.2021.3124385 [23] 李玉龙, 陈晔曜, 崔跃利, 等. LF-UMTI: 基于多尺度空角交互的无监督多曝光光场图像融合[J]. 光电工程, 2024, 51 (6): 240093. doi: 10.12086/oee.2024.240093 Li Y L, Chen Y Y, Cui Y L, et al. LF-UMTI: unsupervised multi-exposure light field image fusion based on multi-scale spatial-angular interaction[J]. Opto-Electron Eng, 2024, 51 (6): 240093. doi: 10.12086/oee.2024.240093 [24] 武迎春, 王玉梅, 王安红, 等. 基于边缘增强引导滤波的光场全聚焦图像融合[J]. 电子与信息学报, 2020, 42 (9): 2293−2301. doi: 10.11999/JEIT190723 Wu Y C, Wang Y M, Wang A H, et al. Light field all-in-focus image fusion based on edge enhanced guided filtering[J]. J Electron Inf Technol, 2020, 42 (9): 2293−2301. doi: 10.11999/JEIT190723 [25] Wu Y C, Wang Y M, Liang J, et al. Light field all-in-focus image fusion based on spatially-guided angular information[J]. J Vis Commun Image Represent, 2020, 72: 102878. doi: 10.1016/j.jvcir.2020.102878 [26] Liu J, Tang J, Wu G S. Residual feature distillation network for lightweight image super-resolution[C]//Proceedings of 2020 European Conference on Computer Vision Workshops, Glasgow, 2020: 41–55. https://doi.org/10.1007/978-3-030-67070-2_2. [27] Rerabek M, Ebrahimi T. New light field image dataset[C]//Proceedings of the 8th International Conference on Quality of Multimedia Experience, Lisbon, 2016. [28] Honauer K, Johannsen O, Kondermann D, et al. A dataset and evaluation methodology for depth estimation on 4D light fields[C]//Proceedings of the 13th Asian Conference on Computer Vision, Taipei, China, 2017, 10113 : 19–34. https://doi.org/10.1007/978-3-319-54187-7_2. [29] Wanner S, Meister S, Goldluecke B. Datasets and benchmarks for densely sampled 4D light fields[C]// Proceedings of the 18th International Workshop on Vision, Lugano, 2013: 225–226. [30] Le Pendu M, Jiang X R, Guillemot C. Light field inpainting propagation via low rank matrix completion[J]. IEEE Trans Image Process, 2018, 27 (4): 1981−1993. doi: 10.1109/TIP.2018.2791864 [31] Vaish V, Adams A. The (new) Stanford light field archive[EB/OL]. [2024-3-15]. http://lightfield.stanford.edu/. [32] Lim B, Son S, Kim H, et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, 2017: 136–144. https://doi.org/10.1109/CVPRW.2017.151. [33] Zhang Y L, Li K P, Li K, et al. Image super-resolution using very deep residual channel attention networks[C]//Proceedings of the 15th European Conference on Computer Vision, Munich, 2018: 286–301. https://doi.org/10.1007/978-3-030-01234-2_18. -
Overview
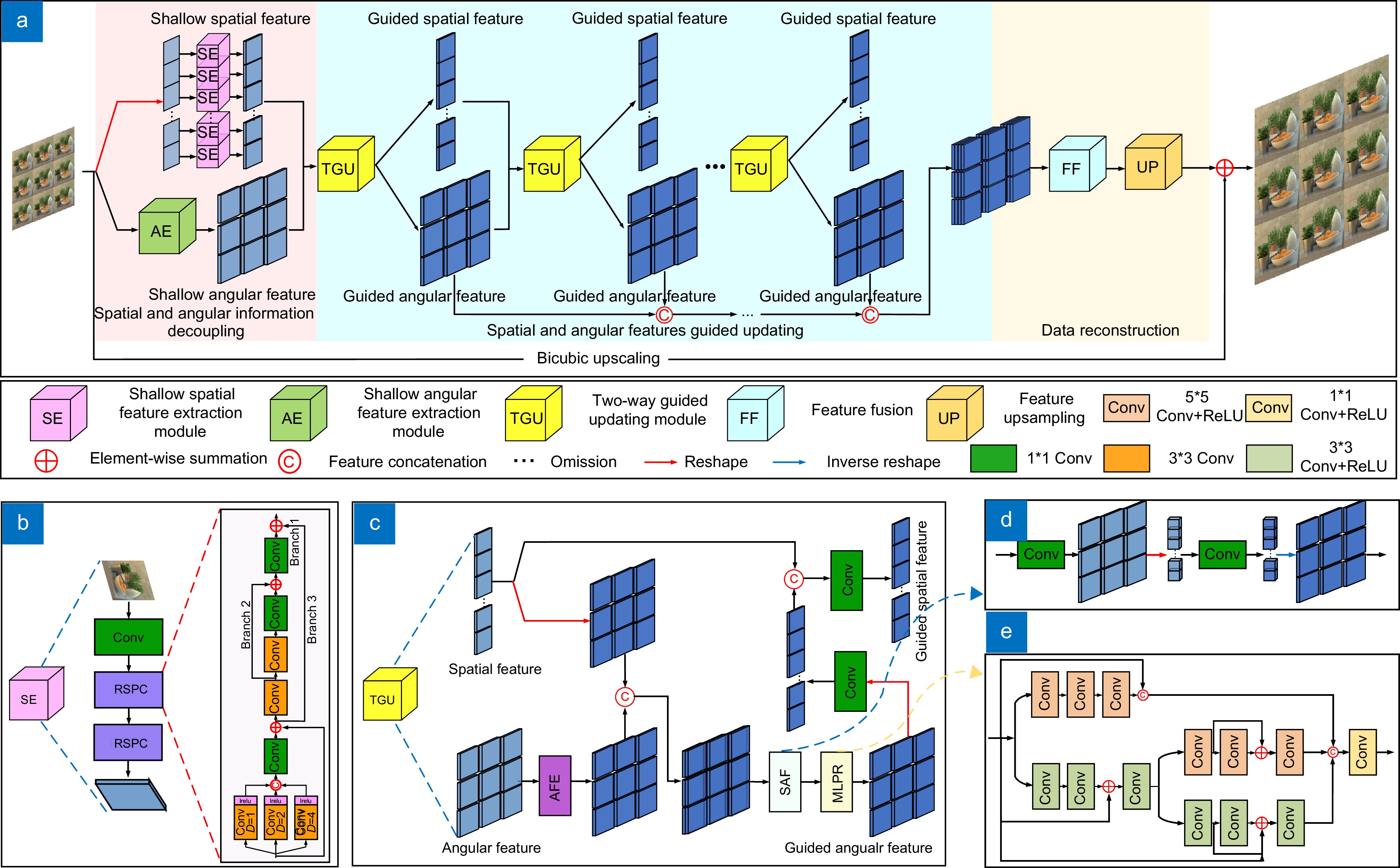
Based on the two-plane representation model, the light field camera captures both spatial and angular information of a three-dimensional scene, which causes the spatial resolution decline of the light field image. To improve the spatial resolution, a two-way guided updating super-resolution network is constructed in this work. In the shallow layers of the network, a double-branch structure is adopted. A series-parallel convolution (RSPC) block based on the atrous spatial pyramid is designed in each branch to decouple the spatial and angular information from different forms of image arrays. Then, based on the ideas of enhancement, fusion, and re-enhancement, a two-way guide updating (TGU) module is designed to complete the iterative update of the decoupled spatial and angular information. Finally, the updated angular information at different layers is fed into the simplified residual feature distillation (SRFD) module to realize data reconstruction and upsampling. Based on effectively controlling complexity, this network adopts a two-way guided updating mechanism to collect light field features of different levels, achieving better super-resolution results. The design concepts for each part of the network are as follows:
1) When decoupling spatial information and angular information, different forms of image arrays are used as inputs to extract the inherent features of each sub-aperture image and the overall parallax structure of the 4D light field through the RSPC block. The RSPC initially employs three atrous convolutions with varying atrous rates in parallel to achieve feature extraction at different levels. Subsequently, it cascades three convolutions of differing sizes to enhance feature extraction. Finally, a residual structure is introduced to mitigate network degradation.
2) In the middle part of the network, TGU module is repeatedly used to iteratively update the decoupled spatial information and angular information. The angular features are first enhanced by TGU module, then fuse with the spatial features and feed into a multi-level perception residual module to obtain the updated angular features. The updated angular features are integrated with the original spatial features, then channel reduction is performed to obtain the updated spatial features.
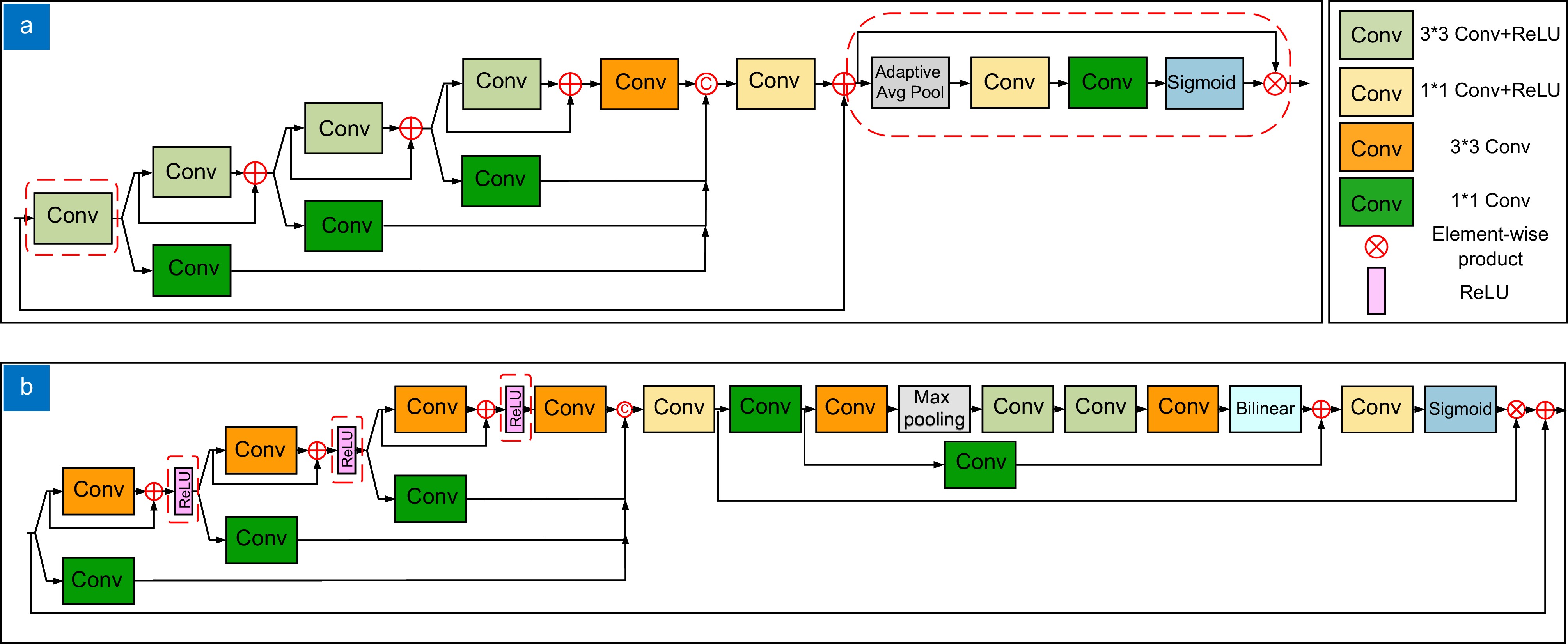
3) The SRFD module is presented to facilitate data reconstruction. In comparison to the residual feature distillation (RFD) network, SRFD uses channel attention to replace the CCA layer in the RFD, which results in fewer parameters and better performance.
Numerous experimental results on public light field datasets have confirmed that our proposed method achieves state-of-the-art performance both in qualitative analysis and quantitative evaluation.
-
Access History
Figures(8)
Tables(3)
Article Metrics

Export File
Citation
Huang L, Lv T Q, Wu Y C, et al. Two-way guided updating network for light field image super-resolution[J]. Opto-Electron Eng, 2024, 51(12): 240222. doi: 10.12086/oee.2024.240222
Format
Content
 DownLoad:
DownLoad:



-
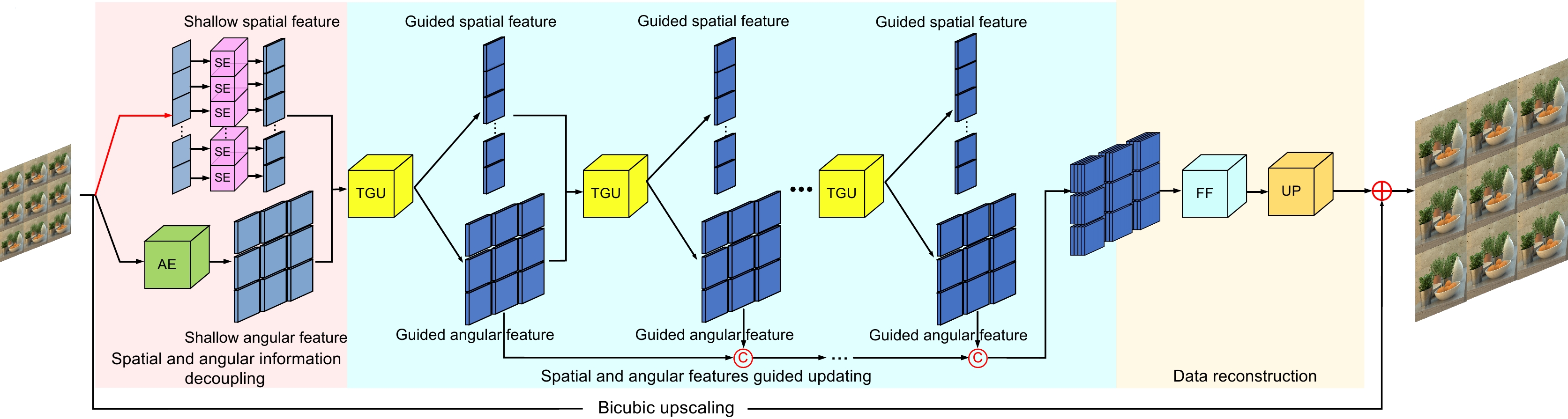
Figure 1.
An overview of our diagram. (a) Overall network architecture diagram; (b) SE module; (c) TGU module; (d) SAF module; (e) MLPR module
-
Figure 2.
Comparison between SFRD and FRD. (a) SRFD module; (b) RFD module
-
Figure 3.
Visual results of the “Origima” and “Bicycle” scene with 2×SR
-
Figure 4.
Visual results of the “Bedroom” and “LEGO Knights” scene with 4×SR
-
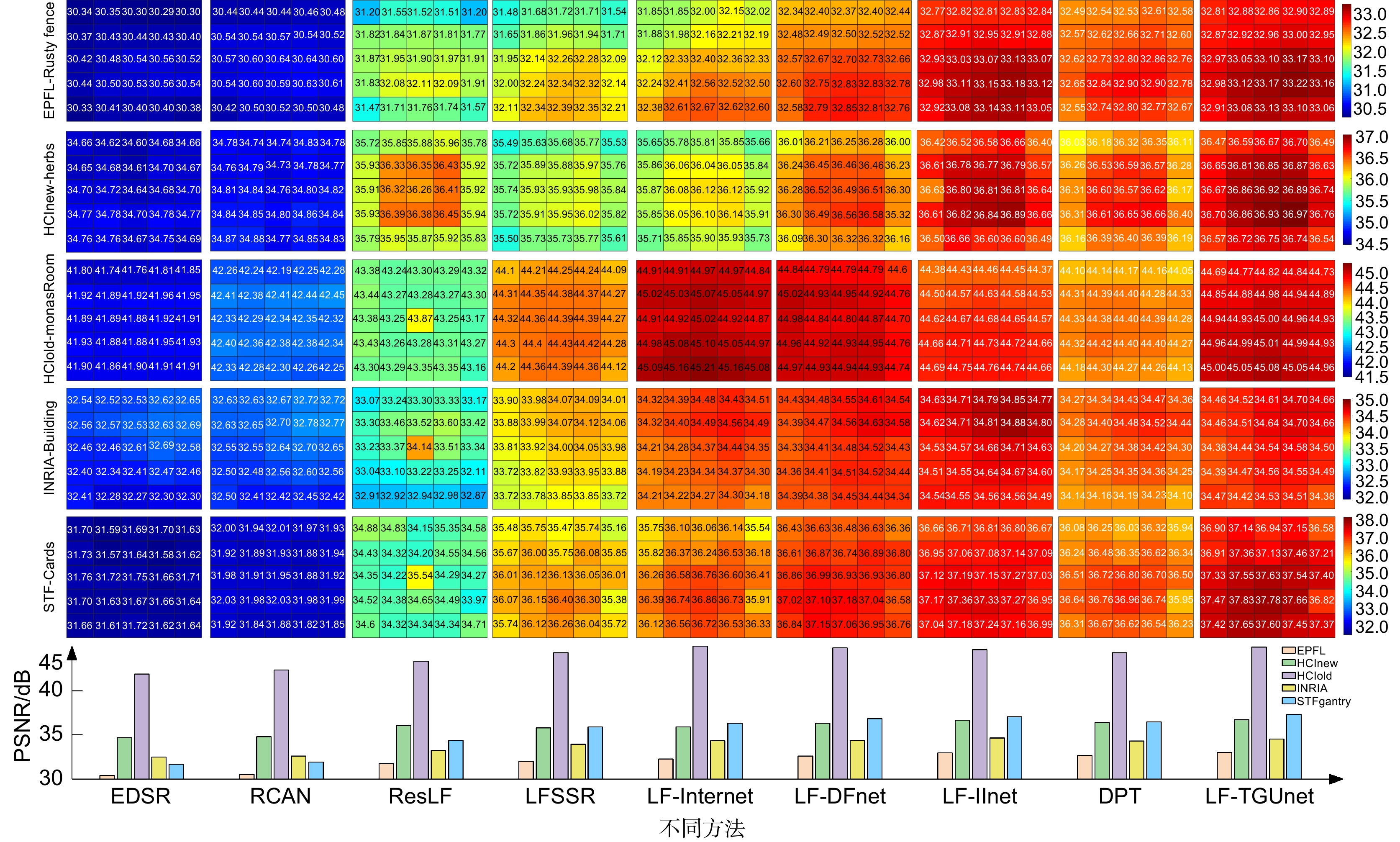
Figure 5.
A visualization of PSNR distribution among different perspectives on 5×5 LFs for 2×SR
-
Figure 6.
Variations of each module. (a) RSPC w/o parallel convolution; (b) RSPC w/o series convolution; (c) RSPC w/o residual; (d) Half TGU
-
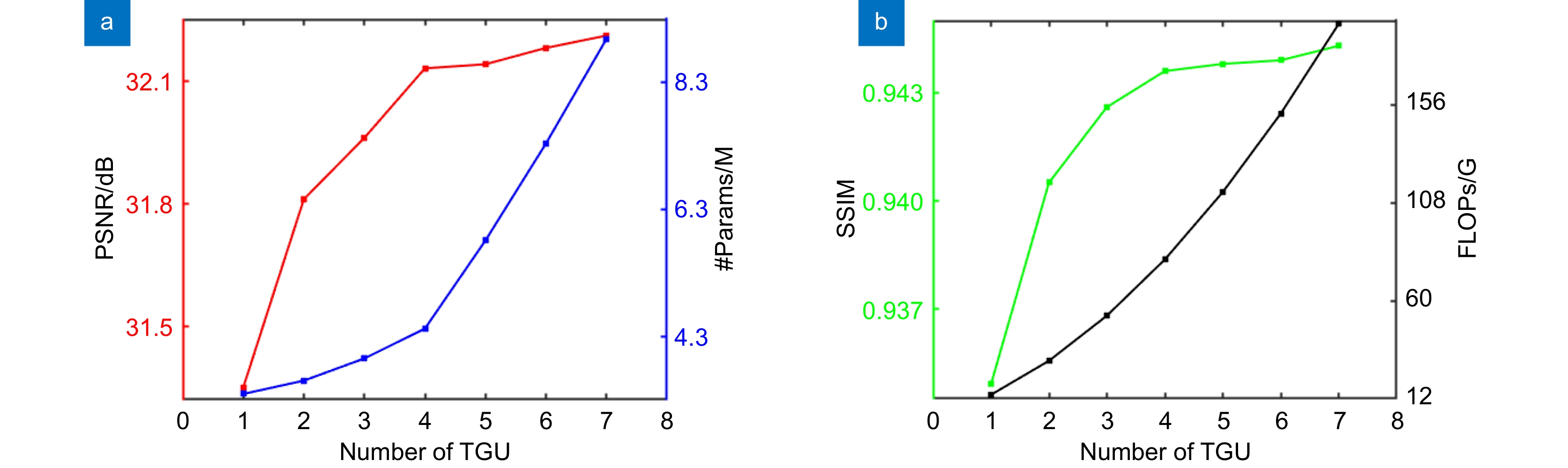
Figure 7.
Optimal selection of the number of TGUs. (a) PSNR and the number of parameters values increase with the number of TGUs; (b) SSIM and FLOPs values increase with the number of TGUs
- Figure .


