
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Wang YYD, Wang H, Gu M. High performance “non-local” generic face reconstruction model using the lightweight Speckle-Transformer (SpT) UNet. Opto-Electron Adv 6, 220049 (2023). doi: 10.29026/oea.2023.220049

|
High performance “non-local” generic face reconstruction model using the lightweight Speckle-Transformer (SpT) UNet
-
Abstract
Significant progress has been made in computational imaging (CI), in which deep convolutional neural networks (CNNs) have demonstrated that sparse speckle patterns can be reconstructed. However, due to the limited “local” kernel size of the convolutional operator, for the spatially dense patterns, such as the generic face images, the performance of CNNs is limited. Here, we propose a “non-local” model, termed the Speckle-Transformer (SpT) UNet, for speckle feature extraction of generic face images. It is worth noting that the lightweight SpT UNet reveals a high efficiency and strong comparative performance with Pearson Correlation Coefficient (PCC), and structural similarity measure (SSIM) exceeding 0.989, and 0.950, respectively.-
Keywords:
- speckle reconstruction /
- non-local model /
- generic face images /
- lightweight network
-
-
References
[1] Goodman JW. Speckle Phenomena in Optics: Theory and Applications (Roberts and Company Publishers, Englewood, 2007). [2] Barbastathis G, Ozcan A, Situ GH. On the use of deep learning for computational imaging. Optica 6, 921–943 (2019). doi: 10.1364/OPTICA.6.000921 [3] Li W, Xi TL, He SF, Liu LX, Liu JP et al. Single-shot imaging through scattering media under strong ambient light interference. Opt Lett 46, 4538–4541 (2021). doi: 10.1364/OL.438017 [4] Li S, Deng M, Lee J, Sinha A, Barbastathis G. Imaging through glass diffusers using densely connected convolutional networks. Optica 5, 803–813 (2018). doi: 10.1364/OPTICA.5.000803 [5] Li YZ, Xue YJ, Tian L. Deep speckle correlation: a deep learning approach toward scalable imaging through scattering media. Optica 5, 1181–1190 (2018). doi: 10.1364/OPTICA.5.001181 [6] Guo EL, Zhu S, Sun Y, Bai LF, Zuo C et al. Learning-based method to reconstruct complex targets through scattering medium beyond the memory effect. Opt Express 28, 2433–2446 (2020). doi: 10.1364/OE.383911 [7] Liao MH, Zheng SS, Pan SX, Lu DJ, He WQ et al. Deep-learning-based ciphertext-only attack on optical double random phase encryption. Opto-Electron Adv 4, 200016 (2021). doi: 10.29026/oea.2021.200016 [8] Liao K, Chen Y, Yu ZC, Hu XY, Wang XY et al. All-optical computing based on convolutional neural networks. Opto-Electron Adv 4, 200060 (2021). doi: 10.29026/oea.2021.200060 [9] Lei YS, Guo YH, Pu MB, He Q, Gao P et al. Multispectral scattering imaging based on metasurface diffuser and deep learning. Phys Status Solidi Rapid Res Lett 16, 2100469 (2022). doi: 10.1002/pssr.202100469 [10] Ma J, Huang YJ, Pu MB, Xu D, Luo J et al. Inverse design of broadband metasurface absorber based on convolutional autoencoder network and inverse design network. J Phys D Appl Phys 53, 464002 (2020). doi: 10.1088/1361-6463/aba3ec [11] Wang JY, Tan XD, Qi PL, Wu CH, Huang L et al. Linear polarization holography. Opto-Electron Sci 1, 210009 (2022). doi: 10.29026/oes.2022.210009 [12] Lin ZS, Wang YYD, Wang H et al. Expansion of depth-of-field of scattering imaging based on DenseNet. Acta Optica Sinica 42, 0436001 (2022). doi: 10.3788/AOS202242.0436001 [13] Wang YYD, Wang H et al. High-accuracy, direct aberration determination using self-attention-armed deep convolutional neural networks. Journal of Microscopy 286, 13–21 (2022). doi: 10.1111/jmi.13083 [14] Horisaki R, Takagi R, Tanida J. Learning-based imaging through scattering media. Opt Express 24, 13738–13743 (2016). doi: 10.1364/OE.24.013738 [15] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L et al. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems 6000–6010 (ACM, 2017). [16] Wang YYD, Lin ZS, Wang H, Hu CF, Yang H et al. High-generalization deep sparse pattern reconstruction: feature extraction of speckles using self-attention armed convolutional neural networks. Opt Express 29, 35702–35711 (2021). doi: 10.1364/OE.440405 [17] Lin TY, Wang YX, Liu XY, Qiu XP. A survey of transformers. (2021); https://arxiv.org/abs/2106.04554. [18] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai XH et al. An image is worth 16x16 words: transformers for image recognition at scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR, 2020). [19] Touvron H, Cord M, Douze M, Massa F, Sablayrolles A et al. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning 10347–10357 (PMLR, 2021). [20] Ye LW, Rochan M, Liu Z, Wang Y. Cross-modal self-attention network for referring image segmentation. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition 10494–10503 (IEEE, 2019). [21] Yang FZ, Yang H, Fu JL, Lu HT, Guo BN. Learning texture transformer network for image super-resolution. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition 5790–5799 (IEEE, 2020). [22] Sun C, Myers A, Vondrick C, Murphy K, Schmid C. Videobert: a joint model for video and language representation learning. In Proceedings of 2019 IEEE/CVF International Conference on Computer Vision 7463–7472 (IEEE, 2019). [23] Girdhar R, Carreira JJ, Doersch C, Zisserman A. Video action transformer network. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition 244–253 (IEEE, 2021). [24] Chen HT, Wang YH, Guo TY, Xu C, Deng YP et al. Pre-trained image processing transformer. In Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition 12294–12305 (IEEE, 2021);http://doi.org/10.1109/CVPR46437.2021.01212. [25] Ramesh A, Pavlov M, Goh G, Gray S, Voss C et al. Zero-shot text-to-image generation. In Proceedings of the 38th International Conference on Machine Learning 8821–8831 (PMLR, 2021). [26] Khan S, Naseer M, Hayat M, Zamir SW, Khan FS et al. Transformers in vision: a survey. (2021);https://arxiv.org/abs/2101.01169. [27] Liu Z, Lin YT, Cao Y, Hu H, Wei YX et al. Swin transformer: hierarchical vision transformer using shifted windows. In Proceedings of 2021 IEEE/CVF International Conference on Computer Vision 9992–10002 (IEEE, 2021). [28] He KM, Zhang XY, Ren SQ, Sun J. Deep residual learning for image recognition. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition 770–778 (IEEE, 2016); http://doi.org/10.1109/CVPR.2016.90. [29] Huang GB, Mattar M, Berg T, Learned-Miller E. Labeled faces in the wild: a database forstudying face recognition in unconstrained environments. In Proceedings of Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition (HAL, 2008). -
Access History

Figures(7)
Tables(3)
Article Metrics

Export File
Citation
Wang YYD, Wang H, Gu M. High performance “non-local” generic face reconstruction model using the lightweight Speckle-Transformer (SpT) UNet. Opto-Electron Adv 6, 220049 (2023). doi: 10.29026/oea.2023.220049
Format
Content
 DownLoad:
DownLoad:


-
Figure 1.
SpT UNet architecture for spatially dense feature reconstruction (a) with the multi-head attention (or cross attention) module (b) included transformer encoder block (c) and decoder block (d).
-
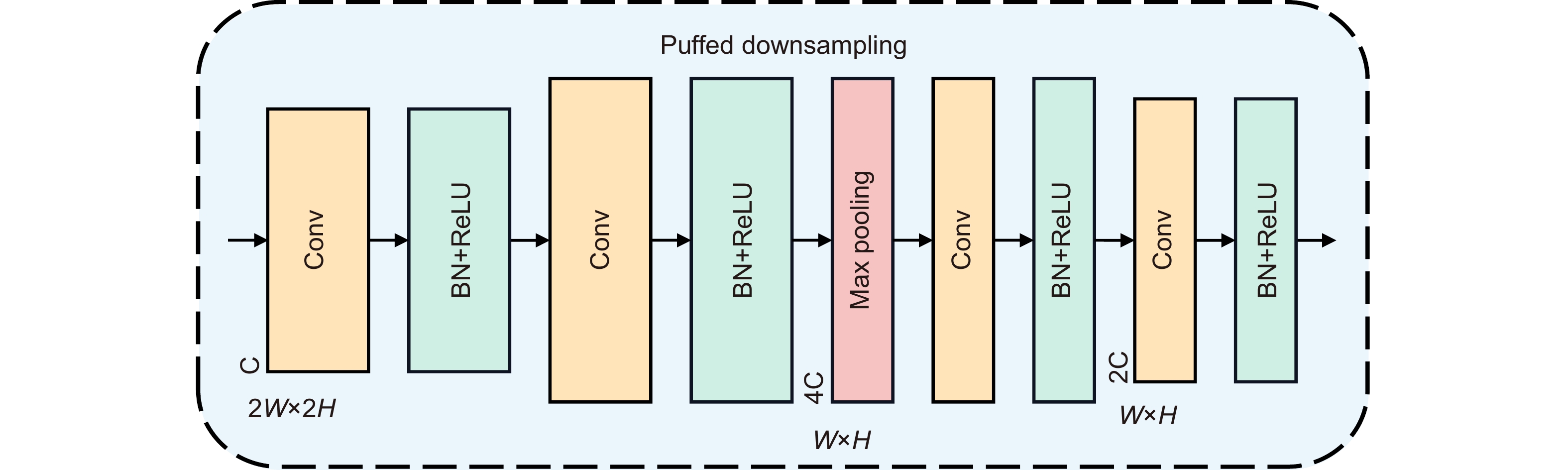
Figure 2.
The puffed downsampling - module architecture.
-
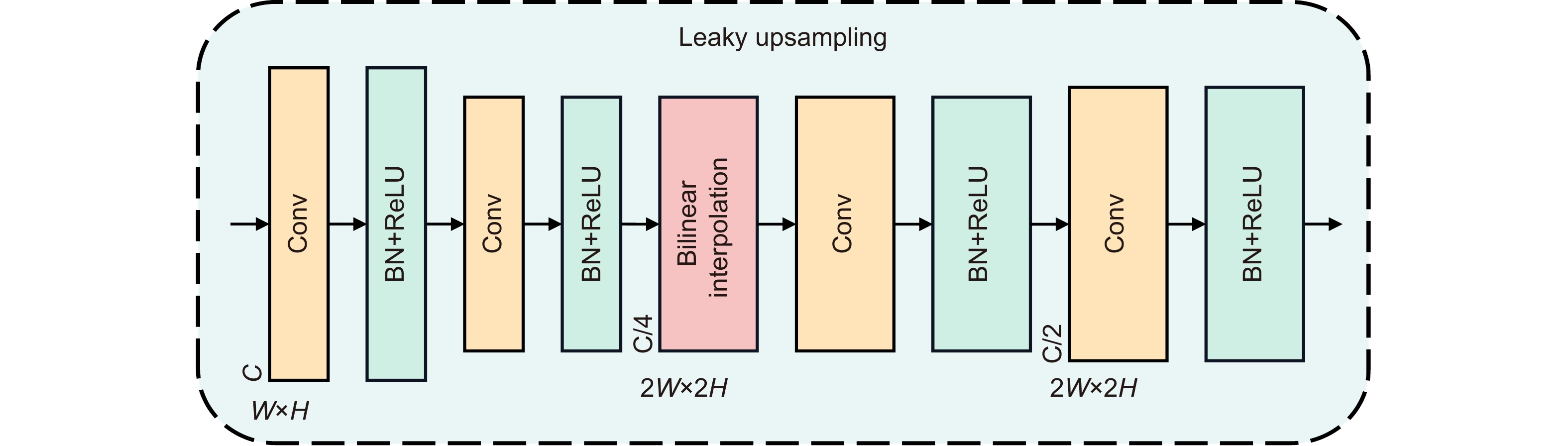
Figure 3.
The leaky upsampling - module architecture.
-
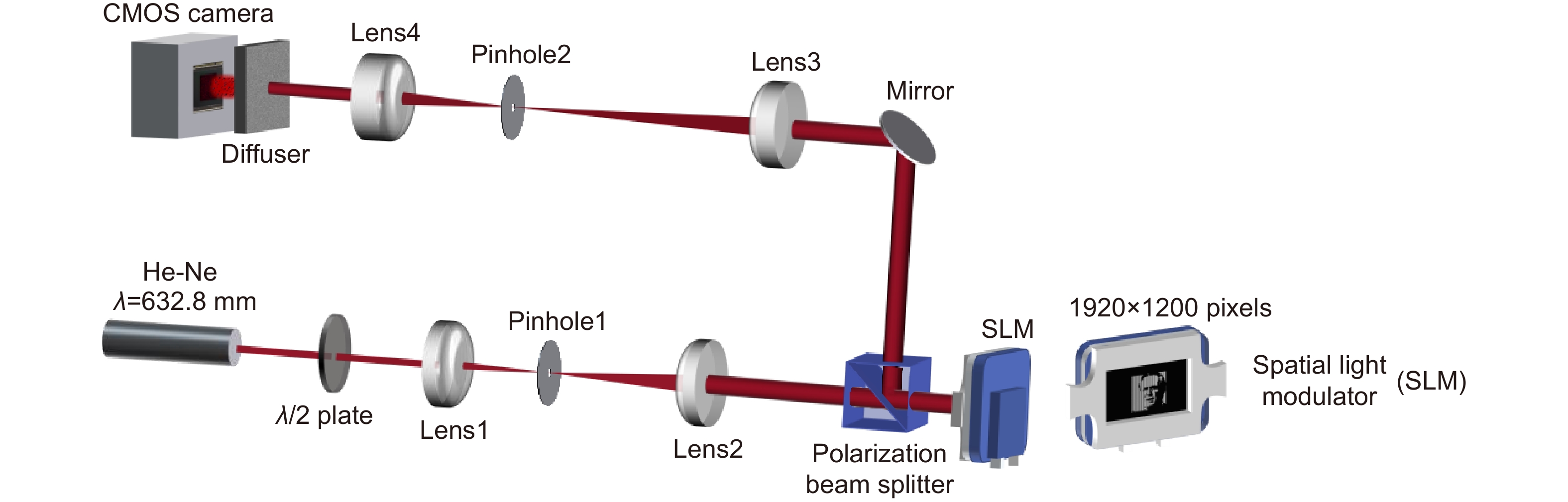
Figure 4.
Experiment set-up.
-
Figure 5.
Overview of the data acquisition under various conditions and the training/testing/validation of the SpT UNet. (a) The training/testing data set is captured at T1 (0 mm), and T2 (20 mm). And the validation data set is captured at T3 (40 mm). The training/testing stage (b) and the validation stage (c) of the SpT UNet for the speckle reconstruction of the generic face images.
-
Figure 6.
The ground truth (left column) and prediction (right column) of the trained SpT UNet with the camera placed at 40 mm away from the focal plane. The prediction results are overlaid with the true positive (white), false positive (green), and false negative (red).
-
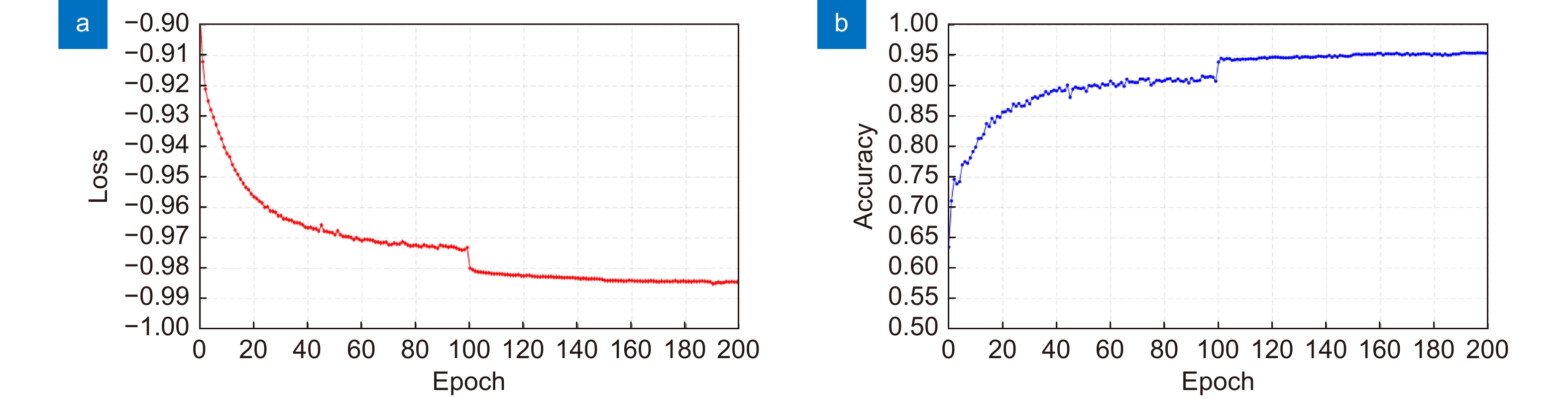
Figure 7.
Quantitative analysis of the trained SpT UNet using NPCC as the loss function (a) and SSIM as the indicator for accuracy (b).


