
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |

|
A weakly supervised learning method for vehicle identification code detection and recognition
-
Abstract
The vehicle identification code (VIN) is of great significance to the annual vehicle inspection. However, due to the lack of character-level annotations, it is impossible to perform the single-character style check on the VIN. To solve this problem, a single-character detection and recognition framework for VIN is designed and a weakly supervised learning algorithm without character-level annotation is proposed for this framework. Firstly, the feature information of each level of VGG16-BN is fused to obtain a fusion feature map with single-character position information and semantic information. Secondly, a network structure for both the character detection branch and the character recognition branch is designed to extract the position and semantic information of a single character in the fusion feature map. Finally, using the text length and single-character category information, the proposed framework is weakly supervised on the vehicle identification code data set without character-level annotations. On the VIN test set, experimental results show that the proposed method realizes the Hmean score of 0.964 and a single-character detection and recognition accuracy rate of 95.7%, showing high practicability. -
-
References
[1] Subedi B, Yunusov J, Gaybulayev A, et al. Development of a low-cost industrial OCR system with an end-to-end deep learning technology[J]. IEMEK J Embedded Syst Appl, 2020, 15(2): 51–60. [2] Rashtehroudi A R, Shahbahrami A, Akoushideh A. Iranian license plate recognition using deep learning[C]//Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), 2020: 1–5. [3] Naz S, Khan N H, Zahoor S, et al. Deep OCR for Arabic script‐based language like Pastho[J]. Expert Syst, 2020, 37(5): e12565. [4] Liao M H, Wan Z Y, Yao C, et al. Real-time scene text detection with differentiable binarization[C]//Proceedings of the AAAI, 2020: 11474–11481. [5] Liu Y L, Chen H, Shen C H, et al. ABCNet: real-time scene text spotting with adaptive Bezier-curve network[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9809–9818. [6] Tian Z, Huang W L, He T, et al. Detecting text in natural image with connectionist text proposal network[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 56–72. [7] Ma J Q, Shao W Y, Ye H, et al. Arbitrary-oriented scene text detection via rotation proposals[J]. IEEE Trans Multimed, 2018, 20(11): 3111–3122. doi: 10.1109/TMM.2018.2818020 [8] Zhou X Y, Yao C, Wen H, et al. East: an efficient and accurate scene text detector[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5551–5560. [9] Long S B, Ruan J Q, Zhang W J, et al. Textsnake: a flexible representation for detecting text of arbitrary shapes[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 20–36. [10] Baek Y, Lee B, Han D Y, et al. Character region awareness for text detection[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9365–9374. [11] Shi B G, Yang M K, Wang X G, et al. ASTER: an attentional scene text recognizer with flexible rectification[J]. IEEE Trans Pattern Anal Mach Intell, 2019, 41(9): 2035–2048. doi: 10.1109/TPAMI.2018.2848939 [12] Wang Q Q, Huang Y, Jia W J, et al. FACLSTM: ConvLSTM with focused attention for scene text recognition[J]. Sci China Inf Sci, 2020, 63(2): 120103. doi: 10.1007/s11432-019-2713-1 [13] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2016, 39(11): 2298–2304. [14] Liao M H, Zhang J, Wan Z, et al. Scene text recognition from two-dimensional perspective[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 8714–8721. [15] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91–99. [16] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21–37. [17] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems, 2012: 1097–1105. [18] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Comput, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735 [19] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd International Conference on Machine Learning, 2006: 369–376. [20] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[Z]. arXiv: 1409.1556, 2014. [21] Luo W J, Li Y J, Urtasun R, et al. Understanding the effective receptive field in deep convolutional neural networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 4905–4913. [22] Zhu X Z, Hu H, Lin S, et al. Deformable ConvNets V2: more deformable, better results[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9308–9316. [23] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2315–2324. [24] Karatzas D, Shafait F, Uchida S, et al. ICDAR 2013 robust reading competition[C]//Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, 2013: 1484–1493. [25] Zhang S Y, Lin M D, Chen T S, et al. Character proposal network for robust text extraction[C]//2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016: 2633–2637. [26] Vincent L, Soille P. Watersheds in digital spaces: an efficient algorithm based on immersion simulations[J]. IEEE Trans Pattern Anal Mach Intell, 1991, 13(6): 583–598. doi: 10.1109/34.87344 [27] Kingma D P, Ba J. Adam: a method for stochastic optimization[Z]. arXiv: 1412.6980, 2014. -
Overview

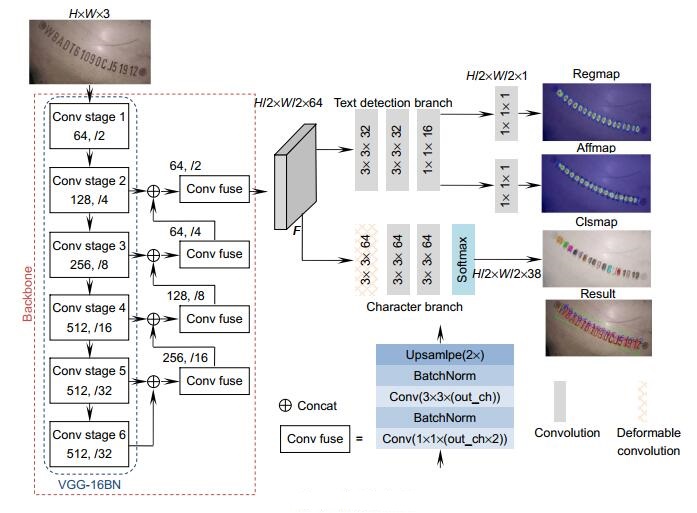
Overview: The vehicle identification number (VIN) is a combination of 17 letters and numbers. It is a unique set of numbers on the car. It plays an important role in verifying the unique identity of the vehicle during the annual vehicle inspection. The manual review of VIN consists of two parts: reviewing whether the VIN in the picture matches the actual VIN; reviewing whether the VIN character style (font type) in the picture is consistent with the VIN extension style. With the development of deep learning technology, the use of computer automatic review has become a trend. The automatic review of VIN can use the universal optical character recognition (OCR) technology. Universal OCR detects and recognizes text from non-specific scenes containing text, which is mainly divided into scene text detection and scene text recognition. The development of scene text detection has mainly gone through three stages: the detection of horizontal text, the detection of text at any angle, and the detection of curved text. There are two main ways of scene text recognition: recognition of the whole text based on the RNN structure and recognition of each character based on the segmentation method. However, due to the lack of character-level annotations, both the text detection method and the text recognition method treat the entire text line as a whole. Since the verification of the character style of VIN needs to detect a single character, we propose a framework to detect and recognize a single character at the same time. In order to solve the problem of lack of character-level annotations in the VIN dataset, we propose a weakly supervised learning algorithm for the framework, which can achieve end-to-end training of the framework. The single character detection and recognition framework proposed in this paper is mainly composed of three parts, namely, backbone, text detection branch, and character branch. Backbone is used to extract the feature F that combines the location and semantic information of the picture. Text detection branch is used to decode single-character position information from F. Character branch is used to extract the category information of a single character from F. The weakly supervised learning algorithm is used to estimate the single-character pseudo-labels, thus completing the training of the framework. The final experimental results show that our framework can not only detect and recognize a single character without character-level annotations, but also achieve good results in detection accuracy and recognition accuracy.
-
Access History
Figures(12)
Tables(4)
Article Metrics

Export File
Citation
Format
Content
 DownLoad:
DownLoad:







-
Figure 1.
Overall framework
-
Figure 2.
Actually effective receptive field[21]
-
Figure 3.
Comparison of different convolution kernels
-
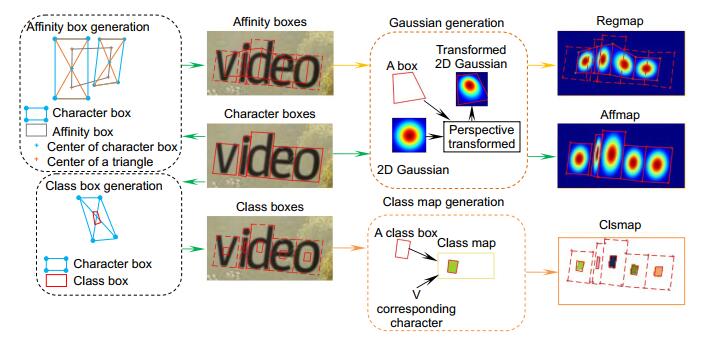
Figure 4.
Label generation for images with character-level annotations
-
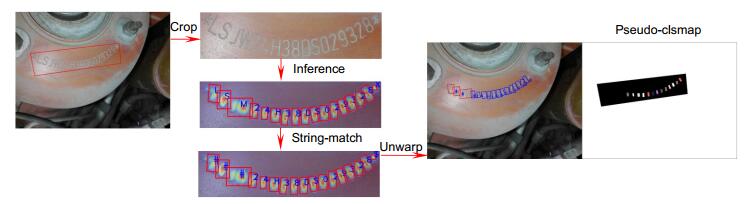
Figure 5.
Pseudo-gt generation for VIN
-
Figure 6.
String matching algorithm
-
Figure 7.
Generation process of character recognition branch pseudo label
-
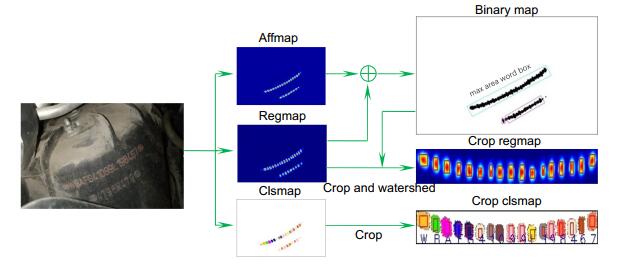
Figure 8.
Reasoning process
-
Figure 9.
Illustration of VIN dataset
-
Figure 10.
Iterative training diagram
-
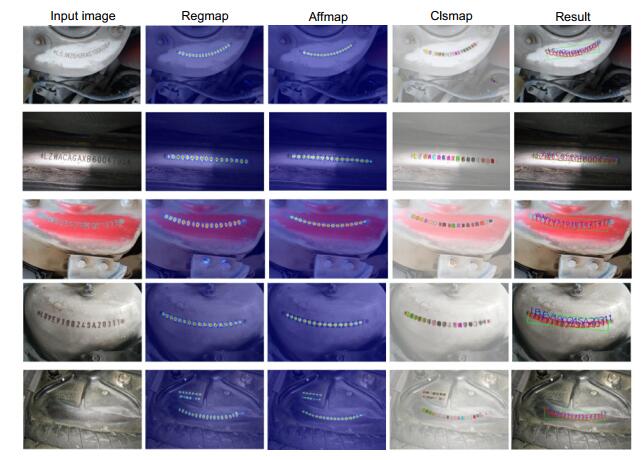
Figure 11.
VIN detection and recognition results
-
Figure 12.
Network output and post-processing results


