
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Fu Xuwen, Zhang Xudong, Zhang Jun, et al. Depth map super-resolution with cascaded pyramid structure[J]. Opto-Electronic Engineering, 2019, 46(11): 180587. doi: 10.12086/oee.2019.180587

|
Depth map super-resolution with cascaded pyramid structure
-
Abstract
Due to the limitation of equipment, the resolution of depth map is low. Depth edges often become blurred when the low-resolution depth image is upsampled. In this paper, we present the pyramid dense residual network (PDRN) to efficiently reconstruct the high-resolution images. The network takes residual network as the main frame and adopts the cascaded pyramid structure for phased upsampling. At each pyramid level, the modified dense block is used to acquire high frequency residual, especially the edge features and the skip connection branch in the residual structure is used to deal with the low frequency information. The network directly uses the low-resolution depth image as the initial input of the network and the subpixel convolution layers is used for upsampling. It reduces the computational complexity. The experiments indicate that the proposed method effectively solves the problem of blurred edge and obtains great results both in qualitative and quantitative.-
Keywords:
- depth map /
- super-resolution /
- pyramid /
- dense residual
-
-
References
[1] Ruiz-Sarmiento J R, Galindo C, Gonzalez J. Improving human face detection through TOF cameras for ambient intelligence applications[C]//Proceedings of the 2nd International Symposium on Ambient Intelligence, 2011: 125–132. [2] Hui T W, Loy C C, Tang X O. Depth map super-resolution by deep multi-scale guidance[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 353–369. [3] Ferstl D, Reinbacher C, Ranftl R, et al. Image guided depth upsampling using anisotropic total generalized variation[C]//Proceedings of 2013 IEEE International Conference on Computer Vision, 2013: 993–1000. [4] He K M, Sun J, Tang X O. Guided image filtering[C]//Proceedings of the 11th European Conference on Computer Vision, 2010: 1–14. [5] 汪荣贵, 汪庆辉, 杨娟, 等.融合特征分类和独立字典训练的超分辨率重建[J].光电工程, 2018, 45(1): 170542. doi: 10.12086/oee.2018.170542 Wang R G, Wang Q H, Yang J, et al. Image super-resolution reconstruction by fusing feature classification and independent dictionary training[J]. Opto-Electronic Engineering, 2018, 45(1): 170542. doi: 10.12086/oee.2018.170542 [6] 王飞, 王伟, 邱智亮.一种深度级联网络结构的单帧超分辨重建算法[J].光电工程, 2018, 45(7): 170729. doi: 10.12086/oee.2018.170729 Wang F, Wang W, Qiu Z L. A single super-resolution method via deep cascade network[J]. Opto-Electronic Engineering, 2018, 45(7): 170729. doi: 10.12086/oee.2018.170729 [7] Richardt C, Stoll C, Dodgson N A, et al. Coherent spatiotemporal filtering, upsampling and rendering of RGBZ videos[J]. Computer Graphics Forum, 2012, 31(2): 247–256. [8] Shen X Y, Zhou C, Xu L, et al. Mutual-structure for joint filtering[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 3406–3414. [9] Kiechle M, Hawe S, Kleinsteuber M. A joint intensity and depth co-sparse analysis model for depth map super-resolution[C]//Proceedings of 2013 IEEE International Conference on Computer Vision, 2013: 1545–1552. [10] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems, 2012: 1097–1105. [11] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91–99. [12] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431–3440. [13] Dong C, Loy C C, He K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295–307. doi: 10.1109/TPAMI.2015.2439281 [14] Wang Z W, Liu D, Yang J C, et al. Deep networks for image super-resolution with sparse prior[C]//Proceedings of IEEE International Conference on Computer Vision, 2015: 370–378. [15] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1646–1654. [16] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2261–2269. [17] Shi W Z, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1874–1883. [18] Lai W S, Huang J B, Ahuja N, et al. Deep laplacian pyramid networks for fast and accurate super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5835–5843. [19] Kopf J, Cohen M F, Lischinski D, et al. Joint bilateral upsampling[J]. ACM Transactions on Graphics, 2007, 26(3): 96. doi: 10.1145/1276377.1276497 [20] Yang Q, Yang R, Davis J, et al. Spatial-depth super resolution for range images[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2007: 1–8. [21] Chan D, Buisman H, Theobalt C, et al. A noise-aware filter for real-time depth upsampling[C]//Proceedings of Workshop on Multi-camera and Multi-modal Sensor Fusion Algorithms and Applications, 2008. [22] Lu J J, Forsyth D. Sparse depth super resolution[C]//Proceedings of 2005 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 2245–2253. [23] Yuan L, Jin X, Li Y G, et al. Depth map super-resolution via low-resolution depth guided joint trilateral up-sampling[J]. Journal of Visual Communication and Image Representation, 2017, 46: 280–291. [24] Diebel J, Thrun S. An application of Markov random fields to range sensing[C]//Advances in Neural Information Processing Systems, 2005: 291–298. [25] Park J, Kim H, Tai Y W, et al. High quality depth map upsampling for 3D-TOF cameras[C]//Proceedings of 2011 IEEE International Conference on Computer Vision, 2011: 1623–1630. [26] Aodha O M, Campbell N D F, Nair A, et al. Patch based synthesis for single depth image super-resolution[C]//Proceedings of the 12th European Conference on Computer Vision, 2012: 71–84. [27] Yang J Y, Ye X C, Li K, et al. Color-guided depth recovery from RGB-D data using an adaptive autoregressive model[J]. IEEE Transactions on Image Processing, 2014, 23(8): 3443–3458. doi: 10.1109/TIP.2014.2329776 [28] Lei J J, Li L L, Yue H J, et al. Depth map super-resolution considering view synthesis quality[J]. IEEE Transactions on Image Processing, 2017, 26(4): 1732–1745. doi: 10.1109/TIP.2017.2656463 [29] Denton E, Chintala S, Szlam A, et al. Deep generative image models using a Laplacian pyramid of adversarial networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 1486–1494. [30] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. [31] He K M, Zhang X Y, Ren S Q, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 1026–1034. [32] Scharstein D, Szeliski R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1–3): 7–42. [33] Scharstein D, Pal C. Learning conditional random fields for stereo[C]//Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition, 2007: 1–8. [34] Scharstein D, Hirschmüller H, Kitajima Y, et al. High-resolution stereo datasets with subpixel-accurate ground truth[C]//Proceedings of the 36th German Conference on Pattern Recognition, 2014: 31–42. [35] Handa A, Whelan T, McDonald J, et al. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM[C]//Proceedings of 2014 IEEE International Conference on Robotics and Automation, 2014: 1524–1531. [36] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010: 249–256. [37] Kingma D, Ba J. Adam: a method for stochastic optimization[C]//Proceedings of the 3rd International Conference on Learning Representations, 2014. [38] Ferstl D, Rüther M, Bischof H. Variational depth superresolution using example-based edge representations[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 513–521. [39] Xie J, Feris R S, Sun M T. Edge guided single depth image super resolution[C]//Proceedings of 2014 IEEE International Conference on Image Processing, 2014: 3773–3777. [40] Song X B, Dai Y C, Qin X Y. Deep depth super-resolution: learning depth super-resolution using deep convolutional neural network[C]//Proceedings of the 13th Asian Conference on Computer Vision, 2017: 360–376. -
Overview

Overview: With the development of science and technology, depth information is gradually applied to various fields of society, such as face recognition, virtual reality and so on. However, due to the limitation of hardware conditions such as sensors, the resolution of the depth images is too low to meet the requirements of the reality. Depth map super- resolution has been an important research area in the field of computer vision. Early methods adopt interpolation, filtering. Although these methods are simple and fast in running, the clues used by these methods are limited and the results are not ideal. The details of the depth map is lost, especially when the upsampling factor is large. To address the above issue, intensity images are used to guide the depth map super-resolution. But when the local structures in the guidance and depth images are not consistent, these techniques may cause the over-texture transferring problem. At present, convolutional neural networks are widely used in computer vision because of its powerful feature representation ability. Several models based on convolutional neural networks have achieved great success in single image super-resolution. To solve the problems of edge blurring and over-texture transferring in depth super-resolution, we propose a new framework to achieve single depth image super-resolution based on the pyramid dense residual network (PDRN). The PDRN directly uses the low-resolution depth image as the input of the network and doesn't require the pre-processing. This can reduce the computational complexity and avoid the additional error. The network takes the residual network as the backbone model and adopts the cascaded pyramid structure for phased upsampling. The result of each pyramid stage is used as the input of the next stage. At each pyramid stage, the modified dense block is used to acquire high frequency residual, and subpixel convolution layer is used for upsampling. The dense block enhances transmission of feature and reduces information loss. Therefore, the network can reconstruct high resolution depth maps using different levels of features. The residual structure is used to shorten the time of convergence and improve the accuracy. In addition, the network adopts the Charbonnier loss function to train the network. By constraining the results of each stage, the training network can get more stable results. Experiments show that the proposed network can avoid edge blurring, detail loss and over-texture transferring in depth map super-resolution. Extensive evaluations on several datasets indicate that the proposed method obtains better performance comparing to other state-of-the-art methods.
-
Access History
Figures(8)
Tables(8)
Article Metrics

Export File
Citation
Fu Xuwen, Zhang Xudong, Zhang Jun, et al. Depth map super-resolution with cascaded pyramid structure[J]. Opto-Electronic Engineering, 2019, 46(11): 180587. doi: 10.12086/oee.2019.180587
Format
Content
 DownLoad:
DownLoad:





-
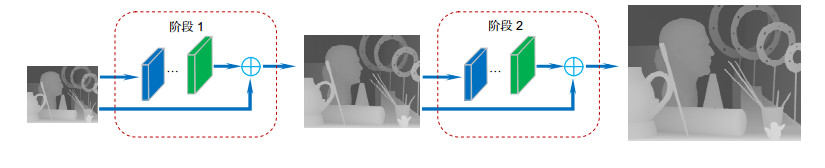
Figure 1.
The network structure. It is for upscale factor 4 that contains two stages. The upscale factor for each stage is 2 and the output of one stage is used as the input of the next stage
-
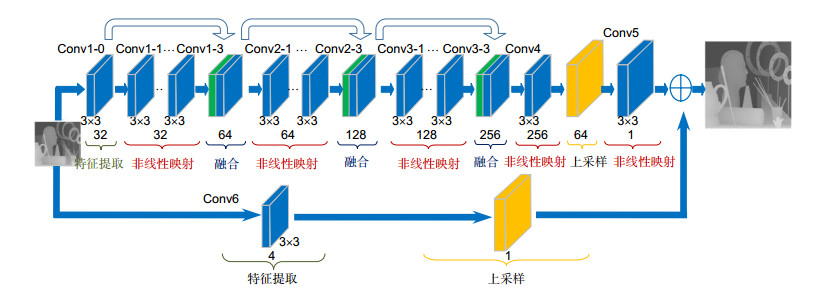
Figure 2.
The single stage of the pyramid dense residual network (PDRN) for upscale factor 2. It contains four operations: feature extraction, non-linear, fusion and upsampling
-
Figure 3.
Reconstruction results and spectrum analysis. (a) Final result and corresponding spectrum analysis; (b) Residual result and its spectrum analysis; (c) Skip connection result and its spectrum analysis
-
Figure 4.
(a) The original dense block; (b) Our dense block that the number of feature maps is changed from 32 to 256 through three skip connections
-
Figure 5.
Reconstruction results for scale factor 4. (a) Ground truth; (b) Nearest; (c) Bicubic; (d) PDN; (e) PDRN
-
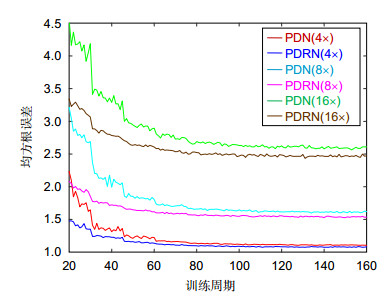
Figure 6.
Convergent curve
-
Figure 7.
Upsampling depth map. (a) Ground truth; (b) TGV[3]; (c) AP[27]; (d) MS-Net[2]; (e) LapSRN[18]; (f) Ours
-
Figure 8.
Upsampling depth map. (a) Ground truth; (b) Bicubic; (c) Xie[39]; (d) MS-Net[2]; (e) LapSRN[18]; (f) Ours


