
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
对于包含成百上千可移动声源的虚拟场景,由于聚类阶段所需运算代价过高,传统的空间声音渲染方案往往需要占用过多的运算资源。这已经成为VR音频渲染技术发展的瓶颈。本文在声音采样的过程中运用分数阶傅里叶变换这一工具,降低了模数转换阶段的量化噪声。此外,通过在聚类这一步骤中添加平均角度偏差阈值的方法提高了声音处理的运算速度,改善了整个系统的运算效率。设计并进行一项感知用户实验,证实了在可视情况下,人对不同类声源聚类产生的空间误差更加敏感这一观点。根据这一结论,本文提出了一种新的空间声音聚类方法,在可视情况下降低了不同类声源聚类为一组的可能性。
 Abstract:
Abstract:Based on the virtual scene containing hundreds of movable sound sources, due to the high computational cost of clustering stage, the traditional spatial sound rendering schemes often take up too much computing resources, which have become a bottleneck in the development of VR audio rendering technology. In this paper, we use fractional Fourier transform (FRFT) as a tool in sound sampling to reduce the quantization noise during the ADC conversion stage. Moreover, we improve the processing speed of sound rendering and the operation efficiency of the entire system by adding the average angle deviation threshold in the clustering step. In addition, we design and implement a perceptual user experiment, and validates the notion that people are more susceptible to spatial errors in different types of sound sources, especially if it is visible. Based on this conclusion, this paper proposes an improved method of sound clustering, which reduces the possibility of clustering different types of sound sources.
-
Key words:
- sound rendering /
- clustering /
- perceived user experiments /
- average angle error
-

Overview: In the field of VR, spatial sound rendering technology plays an increasingly important role. The spatial sense of sound plays a very important role in enhancing the immersive sense of the user in the VR scene. At present, the advanced space sound rendering scheme is mainly divided into two types: the sound waveform and the ray-based tracking algorithm. Recently, important research includes the following points: Tsingos proposed a dynamic spatial sound rendering method based on culling and clustering, which made it possible to process large-scale sound sources in real time. Moeck considered the visual factors during clustering, which reduced the clustering cost. The new algorithm proposed by Schissler eliminated the impact of obstacles on the clustering results. Tao et al. proposed quantization noise suppression method based on fractional Fourier transform to improve the quality of the audio signal sampling. Based on the virtual scene containing hundreds of movable sound sources, due to the high computational cost of clustering stage, the traditional spatial sound rendering scheme often takes up too much computing resources, which has become a bottleneck in the development of VR audio rendering technology. In this paper, we improve the processing speed of sound rendering and the operation efficiency of the entire system by adding the average angle deviation threshold in the clustering step. In addition, we design and implement a perceptual user experiment that validates the notion that people are more susceptible to spatial errors in different types of sound sources, especially if it is visible. Based on this conclusion, this paper proposes an improved method of sound clustering, which reduces the possibility of different types of sound sources clustering. Summarized as follows: focusing on rendering of complex virtual auditory scenes comprising hundreds of moving sound sources using spatial audio mixing, we propose a new clustering algorithm considering average angle error. We presented an effectiveness of our algorithm over specific condition to reduce computational costs caused by frequently clustering. In addition, the result of subjective experiments expresses that the clustering of different types of sound sources will cause more spatial information errors. Using this result, this paper proposes a method based on sound source label parameters, which solves the problem of clustering different kinds of sound sources. In the end, three scene experiments verified the feasibility of the new method.
-
-
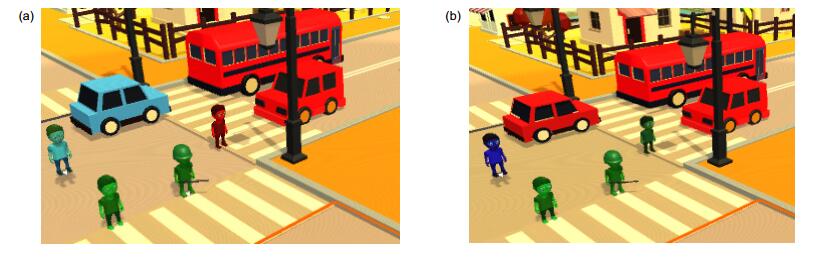
图 3 两种聚类算法的计算结果。(a)传统聚类算法;(b)新型聚类算法
Figure 3. The results of two clustering algorithms. (a) Traditional algorithm; (b) Improved algorithm
表 1 传统方法与新提出的方法的比较
Table 1. Comparison of two methods
聚类数量 声源聚类的可能性/% 平均角度误差/(°) CPU占有率/% 传统方法 新提出的方法 传统方法 新提出的方法 传统方法 新提出的方法 200 64 20 17.3 27.8 18 12 400 56 23 21.1 25.4 36 20 600 60 19 16.5 28.6 68 33 800 52 29 22.4 27.9 87 46  下载: 导出CSV
下载: 导出CSV
表 2 三种场景下算法的性能表现
Table 2. The performance of algorithm in three scenes
环境 声源数量/个 剔除/% 聚类数 聚类时间/ms 帧数/(f·s-1) 街道 769 56 25 0.78 30 办公室 578 64 25 0.62 34 高速公路 893 43 25 0.83 27
下载: 导出CSV
-
[1] Tsingos N, Gallo E, Drettakis G. Perceptual audio rendering of complex virtual environments[J]. ACM Transactions on Graphics, 2003, 23(3): 249-258.
[2] Moeck T, Bonneel N, Tsingos N, et al. Progressive perceptual audio rendering of complex scenes[C]//Proceedings of the 2007 Symposium on Interactive 3D Graphics and Games, 2007: 189-196.
[3] Schissler C, Manocha D. Interactive sound propagation and rendering for large multi-source scenes[J]. ACM Transactions on Graphics, 2016, 36(4): 121-139 http://gamma.cs.unc.edu/MULTISOURCE/paper.pdf
[4] 鲁溟峰, 倪国强, 白廷柱, 等.基于分数阶傅里叶变换的量化噪声抑制方法[J].北京理工大学学报, 2015, 35(12): 1285-1290. http://mall.cnki.net/magazine/Article/BJLG201512014.htm
Lu M F, Ni G Q, Bai T Z, et al. A novel method for suppressing the quantization noise based on fractional Fourier transform[J]. Transactions of Beijing Institute of Technology, 2015, 35(12): 1285-1290. http://mall.cnki.net/magazine/Article/BJLG201512014.htm
[5] ITU. Methods for the subjective assessment of small impairments in audio systems including multichannel sound systems: ITU-R BS. 1116-1[R]. Geneva: ITU, 1994: 1128-1136.
[6] Hochbaum D S, Shmoys D B. A best possible heuristic for the k-center problem[J]. Mathematics of Operations Research, 1985, 10(2): 180-184. doi: 10.1287/moor.10.2.180
[7] Schissler C, Nicholls A, Mehra R. Efficient HRTF-based spatial audio for area and volumetric sources[J]. IEEE Transactions on Visualization and Computer Graphics, 2016, 22(4): 1356-1366. doi: 10.1109/TVCG.2016.2518134
[8] Takala T, Hahn J. Sound rendering[J]. ACM SIGGRAPH Computer Graphics, 1992, 26(2): 211-220. doi: 10.1145/142920
[9] Schissler C, Loftin C, Manocha D. Acoustic classification and optimization for multi-modal rendering of real-world scenes[J]. IEEE Transactions on Visualization and Computer Graphics, 2017, 24(3): 1246-1259. http://gamma.cs.unc.edu/AClassification
[10] Taylor M T, Chandak A, Antani L, et al. RESound: interactive sound rendering for dynamic virtual environments[C]//Proceedings of the 17th ACM International Conference on Multimedia, 2009: 271-280.
[11] Raghuvanshi N, Snyder J, Mehra R, et al. Precomputed wave simulation for real-time sound propagation of dynamic sources in complex scenes[J]. ACM Transactions on Graphics (TOG), 2010, 29(4): 142-149. http://gamma.cs.unc.edu/PrecompWaveSim/docs/paper_docs/paper.pdf
[12] Grelaud D, Bonneel N, Wimmer M, et al. Efficient and practical audio-visual rendering for games using crossmodal perception[C]//Proceedings of the 2009 Symposium on Interactive 3D Graphics and Games, 2009: 177-182.
[13] Innami S, Kasai H. On-demand soundscape generation using spatial audio mixing[C]//Proceedings of 2011 IEEE International Conference on Consumer Electronics, 2011: 29-30.
-
 点击扫一扫
点击扫一扫

图(3)
表(2)
计量
- 文章访问数: 7043
- PDF下载数: 3130
- 施引文献: 0


