
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Cao Tianyang, Cai Haoyuan, Fang Dongming, et al. Robot vision localization system based on image content matching[J]. Opto-Electronic Engineering, 2017, 44(5): 523-533. doi: 10.3969/j.issn.1003-501X.2017.05.008

|
Robot vision localization system based on image content matching
-
Abstract
In order to take advantage of global navigation map for robot self-localization and solve kidnap problem, a robot vision localization system is presented based on graphic content matching. It can make good use of the different objects and their layout in different rooms or corridors to fix robot position, which cannot be disturbed by similar objects. This vision localization system is composed of frames overlap region extraction and overlap region rebuilding through sub-blocks matching, and the interference caused by points on the wall and mismatching sub-blocks can be deleted. The image distortion can be adjusted to the same before matching. In the experiment, this graphic matching method can match the real-time robot vision with keyframes global map effectively, and find out the most similar keyframe for each vision image and fix robot position exactly. More than 95% robot vision can be matched and position RMSE < 0.5 m. Robot can also localize itself effectively when it is kidnapped.-
Keywords:
- robot vision /
- graphic content matching /
- image distortion /
- image overlap region /
- overlap region
-
-
References
[1] Fabian J R, Clayton G M. Adaptive visual odometry using RGB-D cameras[C]// Proceedings of 2014 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Besacon, France, 2014: 1533–1538. [2] 许允喜, 陈方.基于多帧序列运动估计的实时立体视觉定位[J].光电工程, 2016, 43(2): 89–94. Xu Yunxi, Chen Fang. Real-time stereo visual localization based on multi-frame sequence motion estimation[J]. Opto-Electronic Engineering, 2016, 43(2): 89–94. [3] Wang Han, Mou Wei, Suratno H, et al. Visual odometry using RGB-D camera on ceiling Vision[C]// Proceedings of 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 2012: 710–714. [4] 林辉灿, 吕强, 张洋, 等.稀疏和稠密的VSLAM的研究进展[J].机器人, 2016, 38(5): 621–631. Lin Huican, Lü Qiang, Zhang Yang, et al. The sparse and dense VSLAM: a survey[J]. Robot, 2016, 38(5): 621–631. [5] Tateno K, Tombari F, Navab N. Real-time and scalable incremental segmentation on dense SLAM[C]// Proceedings of 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 2015: 4465–4472. [6] Schöps T, Engel J, Cremers D. Dense planar SLAM[C]// Pro-ceedings of 2014 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 2014: 157–164. [7] Schöps T, Engel J, Cremers D. Semi-dense visual odometry for AR on a smartphone[C]// Proceedings of 2014 IEEE Interna-tional Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 2014: 140–150. [8] Engel J, Stuckler J, Cremers D. Large-scale direct SLAM with stereo cameras[C]// Proceedings of 2015 IEEE/RSJ Interna-tional Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 2015: 1935–1942. [9] Mur-Artal R, Montiel J M M, Tardos J D. ORB-SLAM: a versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics, 2015, 31(5): 1147–1163. doi: 10.1109/TRO.2015.2463671 [10] Chen Pengjin, Gu Zhaopeng, Zhang Guodong, et al. Ceiling vision localization with feature pairs for home service robots[C]// Proceedings of the 2014 IEEE International Conference on Robotics and Biomimetics, Bali, Indonesia, 2014: 2274–2279. [11] Choi H, Kim D Y, Hwang J P, et al. CV-SLAM using ceiling boundary[C]// Proceedings of 2010 the 5th IEEE Conference on Industrial Electronics and Applications (ICIEA), Taichung, China, 2010: 228–233. [12] Choi H, Kim R, Kim E. An efficient ceiling-view SLAM using relational constraints between landmarks[J]. International Journal of Advanced Robotic Systems, 2014, 11: 4. doi: 10.5772/57225 [13] Lee S, Lee S, Baek S. Vision-based kidnap recovery with SLAM for home cleaning robots[J]. Journal of Intelligent & Robotic Systems, 2012, 67(1): 7–24. [14] Pfister S T, Burdick J W. Multi-scale point and line range data algorithms for mapping and localization[C]// Proceedings of 2006 IEEE International Conference on Robotics and Automation (ICRA), Orlando, America, 2006: 1159–1166. [15] Jeong W, Lee K M. CV-SLAM: a new ceiling vision-based SLAM technique[C]// Proceedings of 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, Canada, 2005: 3195–3200. [16] 邓集洪, 魏宇星.基于局部特征描述的目标定位[J].光电工程, 2015, 42(1): 58–64. Deng Jihong, Wei Yuxing. Location of object based on local feature descriptor[J]. Opto-Electronic Engineering, 2015, 42(1): 58–64. [17] 黄文有, 徐向民, 吴凤岐, 等.核环境水下双目视觉立体定位技术研究[J].光电工程, 2016, 43(12): 28–33. doi: 10.3969/j.issn.1003-501X.2016.12.005 Huang Wenyou, Xu Xiangmin, Wu Fengqi, et al. Research of underwater binocular vision stereo positioning technology in nuclear condition[J]. Opto-Electronic Engineering, 2016, 43(12): 28–33. doi: 10.3969/j.issn.1003-501X.2016.12.005 [18] J Zhuo, L Sun, J Shi, et al. Research on a Type of Camera Calibration Method Based on High Precision Detection of X Corners[C]// Proceedings of 2015 8th International Symposium on Computational Intelligence and Design (ISCID), -
Overview

Abstract: Self-localization and mapping is an important and difficult problem for mobile robot. Reliable and low cost solution for this issue would promote the development of robotics industry. A robot vision localization system is presented in this paper, which can take advantage of global keyframes navigation map for robot self-localization. And two common problems for robot self-localization, including solve kidnap problem and similar objects interference, can be solved through this localization system, which could fix robot position by matching with global map according to the graphic content in the robot vision. The core of this system is graphic content matching, and composed by two parts: image overlap region extraction and overlap region rebuilding through sub-blocks matching. This method could match image content effectively. If two frames take some same objects, there would be some overlap regions between them. And the overlap regions between two frames can be obtained by translating and rotating these frames according to their matched feature points on the ceiling firstly. And a special designed ceiling feature point extraction and matching method is presented, and the interference caused by points on the wall and mismatching sub-blocks can be deleted according to the features of ceiling structure. After overlap region extraction, the graphic content matching can be processed in these regions. Through image matching, this localization system can make good use of the different objects and their layout in different rooms or corridors as landmarks. These landmarks can be used to fix robot global position precisely in the large indoor space, which is composed of multi-rooms and corridors. By taking advantage of image content, this vision system could make good use of the different objects in different rooms and cannot be disturbed by similar objects, which is common interference for global indoor environment localization. However, there would be some new interference for graphic content matching. The main interference is image distortion, which is caused by camera angle and robot movement. In order to revise image distortion and localize robot exactly, a graphic content matching method is presented. According to the features of image distortion, this matching method is designed through sub-blocks matching in the overlap regions between two frames. It could calculate the images similarity by adjusting the images to the same distortion. In the experiment, this graphic matching method can match the real-time robot vision with global keyframes map effectively, and find out the most similar keyframe for each vision image and fix robot position exactly. More than 95% robot vision can be matched and position RMSE < 0.5 m. Robot can also localize itself effectively when it is kidnapped.
-
Access History

Export File
Citation
Cao Tianyang, Cai Haoyuan, Fang Dongming, et al. Robot vision localization system based on image content matching[J]. Opto-Electronic Engineering, 2017, 44(5): 523-533. doi: 10.3969/j.issn.1003-501X.2017.05.008
Format
Content
 DownLoad:
DownLoad:






-
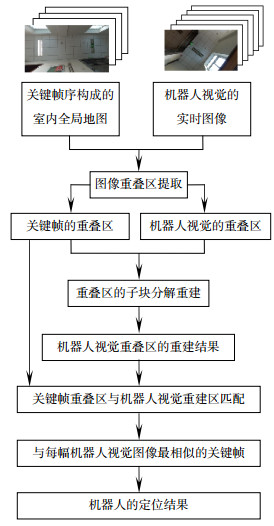
Figure 1.
System structure.
-
Figure 2.
Robot and its vision system.
-
Figure 3.
The global map composed by keyframes (the blocks in the figure is keyframes taken position)
-
Figure 4.
The image rotation and translation.
-
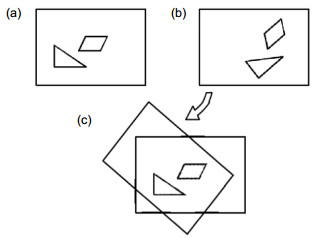
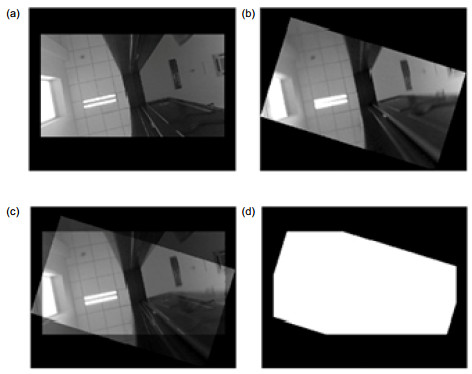
Figure 5.
The rotation and translation result. (a) Keyframe rotation. (b) Robot vision rotation. (c) Overlap region. (d) Overlap region mask.
-
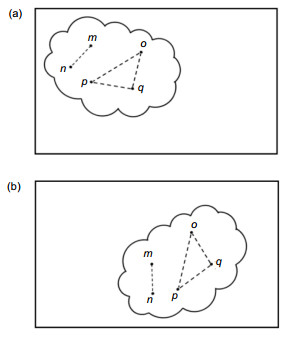
Figure 6.
The features of connect lines and angle of features points. (a) Robot vision. (b) Keyframe.
-
Figure 7.
The screen result of feature points (red points). (a) The feature points in keyframe. (b) The feature points in robot vision. (c) The screen result of feature points in keyframe. (d) The screen result of feature points in robot vision.
-
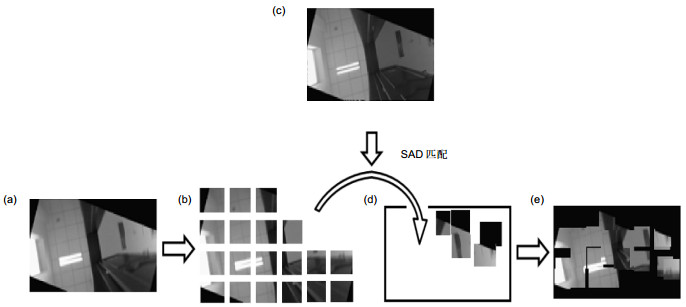
Figure 8.
The process of rebuilding. (a) The overlap region in robot vision. (b) The sub-block division of fig. (a). (c) The overlap region in keyframe. (d) The sub-block rebuilding. (e) The rebuilding result of overlap region of robot vision.
-
Figure 9.
The rebuilding of overlap region. (a) The overlap region in keyframe. (b) The overlap region in robot vision. (c) The rebuilding result of overlap region of robot vision.
-
Figure 10.
The wrong rebuilding overlap region. (a) Keyframe. (b) Robot vision. (b) The overlap region in robot vision. (c) The rebuilding result of overlap region of robot vision.
-
Figure 11.
The experiment result in the corridor. (a) Keyframe. (b) Robot vision. (c) The overlap region in robot vision. (d) The rebuilding result of overlap region of robot vision.
-
Figure 12.
The experiment result in the room. (a) Keyframe. (b) Robot vision. (c) The overlap region in robot vision. (d) The rebuilding result of overlap region of robot vision.
-
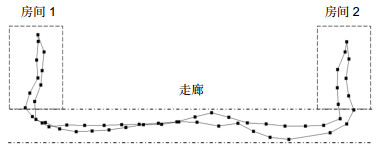
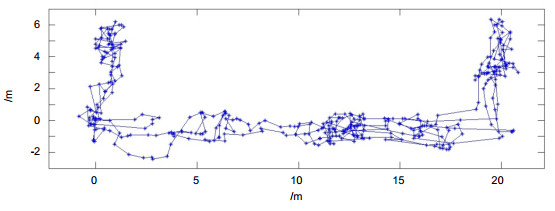
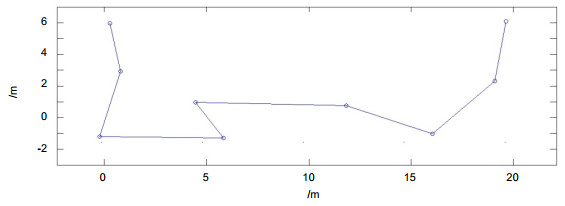
Figure 13.
The localization result and robot (The points are robot localization results).
-
Figure 14.
The localization result when robot is kidnapped("o" is kidnap position when robot is landed)


