
 E-mail Alert
E-mail Alert RSS
RSS
An open-pit mine roadway obstacle warning method integrating the object detection and distance threshold model
-
摘要:
针对当前行车预警方法无法适应露天矿非结构化道路问题,本文提出一种融合目标检测和障碍距离阈值的预警方法。首先根据露天矿障碍特点改进原有的Mask R-CNN检测框架,在骨架网络中引入扩张卷积,在不缩小特征图的情况下扩大感受野范围保证较大目标的检测精度。然后,根据目标检测结果构建线性距离因子,表征障碍物在输入图像中的深度信息,并建立SVM预警模型。最后为了保证预警模型的泛化能力采用迁移学习的方法,在COCO数据集中对网络进行预训练,在文中实地采集的数据集中训练C5阶段和检测层。实验结果表明,本文方法在实地数据检测中精确率达到98.47%,召回率为97.56%,人工设计的线性距离因子对SVM预警模型有良好的适应性。
 Abstract:
Abstract:In order to solve the problem that the current driving warning method cannot adapt to the unstructured road in open-pit mine, this paper proposes an early warning method that integrates target detection and obstacle distance threshold. Firstly, the original Mask R-CNN detection framework was improved according to the characteristics of open-pit mine obstacles, and dilated convolution was introduced into the framework network to expand the receptive field range without reducing the feature map to ensure the detection accuracy of larger targets. Then, a linear distance factor was constructed based on the target detection results to represent the depth information of obstacles in the input image, and an SVM warning model was established. Finally, in order to ensure the generalization ability of the warning model, transfer learning method was adopted to carry out pre-training of the network in COCO data set, and both the C5 stage and detection layer were trained in the data collected in the field. The experimental results show that the accuracy and recall of the proposed method reach 98.47% and 97.56% in the field data detection, respectively, and the manually designed linear distance factor has a good adaptability to the SVM warning model.
-
Key words:
- obstacle warning /
- target detection /
- distance threshold model /
- dilated convolution /
- transfer learning
-

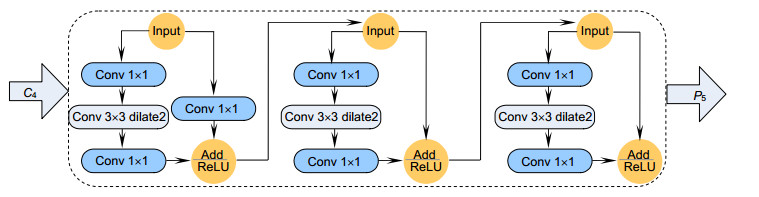
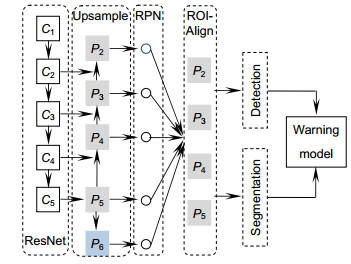
Overview: Most of the researches on traffic obstacle warning based on machine vision mainly focus on urban roads. There are no clear road surface, boundary, and road width standard but many steep curves on open-pit mine roads which are quite different from the urban roads. Thus, the target detection and early warning method suitable for urban roads cannot be applied to non-structural open pit roads. With the emergence of convolutional neural network, target detection and depth estimation based on deep learning gradually surpass the traditional computational vision methods in accuracy and applicability. However, target detection and pixel depth estimation are difficult to implement the underlying convolutional layer sharing mechanism. Usually, the driver will make the early-warning judgment based on the distance threshold according to the experience and other factors. Therefore, an early-warning method combining target detection and the distance threshold model is proposed in this paper. First, the original Mask R-CNN detection framework was improved according to the characteristics of open-pit mine obstacles, and the dilated convolution was introduced in ResNet. Under the condition that the subnet structure and residual connection remain unchanged, the 3 by 3 convolution in the C5 subnet was replaced by the dilated convolution with the dilatation rate of 2, so that the original 3 by 3 receptive field was extended to 7 by 7. The range of the receptive field was expanded to ensure the detection accuracy of the larger target without reducing the feature graph. Then, according to the detection and classification results, the normalized detection frame length, width, area, mask area, and category were used as the depth information to represent the obstacle in the two-dimensional image. Radial basis function SVM warning model was established to judge whether the detected target is a dangerous target. Finally, in order to ensure the generalization ability of the warning model, transfer learning method was adopted to pre-train the network in COCO data, so that sufficient underlying characteristic information was learned in the first four stages. Both C5 stage and detection layer were trained in the data collected in this paper. The experimental results show that the linear distance factor proposed in this paper can effectively represent the depth information of obstacles, and the Mask R-CNN and yolov3 can adapt to the warning model in this paper. The improved Mask R-CNN in this paper pays more attention to the regression and classification of frames with larger targets, with an accuracy rate of 98.47% and a recall rate of 97.56% which are better than other frames.
-
-

图 5 三种算法在多种场景下的预警效果对比图。从左到右分别是Mask R-CNN、本文框架、yolov3经过预警模型分类的检测结果,红色代表检测为预警目标,绿色代表安全目标。(a)会车场景一;(b)会车场景二;(c)会车场景三;(d)跟车场景一;(e)跟车场景二;(f)行人场景;(g)跟车与行人复杂场景;(h)中距离多车交会;(i)近距离多车交会;(j)远距离多车交会
Figure 5. Comparison diagram of three models in various scenarios. From left to right are the detection results of Mask R-CNN, framework of this paper and yolov3 classified by the warning model. The red represents the detection of warning targets and the green represents the security targets. (a) Meeting scene 1; (b) Meeting scene 2; (c) Meeting scene 3; (d) Following the car scene 1; (e) Scene 2 with the car; (f) Pedestrian scene; (g) Complex scenes with cars and pedestrians; (h) Medium-distance multi-vehicle meeting; (i) Close multiple vehicle meeting; (j) Long distance multi-vehicle meeting
表 1 不同特征组合对比
Table 1. Comparisons of different feature combinations
Type Accuracy/% Recall/% F1/% 1 wanchor+hanchor+sanchor+l 88.12 95.13 91.49 2 wanchor+hanchor+smask+l 90.16 92.84 91.48 3 hanchor+sanchor+smask+l 90.22 81.36 85.56 4 wanchor+sanchor+smask+l 94.34 82.64 88.10 5 wanchor+hanchor+sanchor+smask 55.61 64.92 59.51 6 wanchor+hanchor+sanchor+smask+l 98.47 97.56 98.01  下载: 导出CSV
下载: 导出CSV
表 2 三种检测框架对比
Table 2. Comparisons of three detection frameworks
Model Accuracy/% Recall/% F1/% Time/ms yolov3+SVM 95.08 95.31 95.19 87 Mask R-CNN+SVM 96.64 95.89 96.26 134 Ours model 98.47 97.56 98.01 136
下载: 导出CSV
-
[1] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005: 886-893.
[2] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008: 1-8.
[3] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[4] Girshick R. Fast R-CNN[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 1440-1448.
[5] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031
[6] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[7] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517-6525.
[8] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//The 14th European Conference on Computer Vision, 2016: 21-37.
[9] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2980-2988.
[10] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
[11] 杨会成, 朱文博, 童英.基于车内外视觉信息的行人碰撞预警方法[J].智能系统学报, 2019, 14(4): 756-760. doi: 10.11992/tis.201801016
Yang H C, Zhu W B, Tong Y. Pedestrian collision warning system based on looking-in and looking-out visual information analysis[J]. CAAI Transactions on Intelligent Systems, 2019, 14(4): 756-760. doi: 10.11992/tis.201801016
[12] Yang D F, Sun F C, Wang S C, et al. Simultaneous estimation of ego-motion and vehicle distance by using a monocular camera[J]. Science China Information Sciences, 2014, 57(5): 1-10. doi: 10.1007/s11432-013-4884-8
[13] Xu Y F, Wang Y, Guo L. Unsupervised ego-motion and dense depth estimation with monocular video[C]//Proceedings of 2018 IEEE 18th International Conference on Communication Technology, 2018: 1306-1310.
[14] Tateno K, Tombari F, Laina I, et al. CNN-SLAM: real-time dense monocular SLAM with learned depth prediction[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6565-6574.
[15] Teichmann M, Weber M, Zöllner M, et al. MultiNet: real-time joint semantic reasoning for autonomous driving[C]//Proceedings of 2018 IEEE Intelligent Vehicles Symposium (Ⅳ), 2018: 1013-1020.
[16] Li B J, Liu S, Xu W C, et al. Real-time object detection and semantic segmentation for autonomous driving[J]. Proceedings of SPIE, 2017, 10608: 106080P. doi: 10.1117/12.2288713
[17] Chen L F, Yang Z, Ma J J, et al. Driving scene perception network: real-time joint detection, depth estimation and semantic segmentation[C]//Proceedings of 2018 IEEE Winter Conference on Applications of Computer Vision, 2018: 1283-1291.
[18] 彭秋辰, 宋亦旭.基于Mask R-CNN的物体识别和定位[J].清华大学学报(自然科学版), 2019, 59(2): 135-141. doi: 10.16511/j.cnki.qhdxxb.2019.22.003
Peng Q C, Song Y C. Object recognition and localization based on Mask R-CNN[J]. Journal of Tsinghua University (Science and Technology), 2019, 59(2): 135-141. doi: 10.16511/j.cnki.qhdxxb.2019.22.003
[19] Kong H, Audibert J Y, Ponce J. Vanishing point detection for road detection[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009: 96-103.
[20] Moghadam P, Starzyk J A, Wijesoma W S. Fast vanishing-point detection in unstructured environments[J]. IEEE Transactions on Image Processing, 2012, 21(1): 425-430. doi: 10.1109/TIP.2011.2162422
[21] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[22] Li Z M, Peng C, Yu G, et al. DetNet: design backbone for object detection[C]//The 15th European Conference on Computer Vision, 2018: 339-354.
[23] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[EB/OL]. (2016-04-30). https://arxiv.org/abs/1511.07122v2.
-

 点击扫一扫
点击扫一扫
图(5)
表(2)
计量
- 文章访问数: 6173
- PDF下载数: 2137
- 施引文献: 0


